

概述
本文从简化概念、帮助理解作为出发点,对SQL性能优化的概念做一些总结,目的是让读者知道SQL性能优化大概是什么样的一个过程。
为了简化篇幅,减少信息量,一些优化工具、方法也不作展开说明,仅作简单的介绍;性能问题的示例也尽可能从简(我们遇到的SQL性能问题,实际上比本文示例的情况复杂得多)。
在本文中,“SQL性能优化”都特指针对Oracle数据库中的SQL性能优化。
概念结构
关于SQL性能优化,基本就以下几个关键点:
1.SQL优化的本质
2.理解SQL性能问题
3.收集SQL性能问题信息
4.分析问题
5.优化思路&手段
优化本质
SQL查询时,主要的动作是:扫描数据、处理数据(筛选、汇总、去重等)、返回数据(到客户端)。
其中,扫描数据主要是IO操作,其他操作基本都是CPU操作,如果整个SQL查询耗时过长,除去网络因素,IO(这也是当前计算机硬件部分的瓶颈)是占用时间最多的原因(SQL语句中嵌入了PL/SQL代码这种特殊情况除外)。
所以SQL性能优化的本质就是:尽可能减少SQL查询过程中不必要的IO操作。
瞄准这个目标,我们应该就知道SQL性能优化的学习方向是:如何减少SQL查询不必要的IO操作。
理解SQL性能问题
SQL性能问题的本质就是:查询目标数据所需要扫描的数据块(IO操作)过多。
在一篇写得很好的SQL优化指引手册的指引下,我们是可以做到在未掌握甚至未接触过SQL性能优化的情况下解决一些SQL性能问题。
但如果想真正掌握SQL性能优化,我们还是先得理解问题本质,即当我们说一段SQL存在性能问题时,其问题本质是什么。
那么问题来了:
什么是数据块?
SQL查询跟数据块有何关系?
为什么会扫描到过多数据块?
为了便于理解,这里用“快递员取件”打个简单的比方。
在某个时刻,某个快递员需要在他所负责的片区收取100个大小不同的包裹,这100个包裹分散在10个不同的地点。他规划好路线之后,先后开车到这10个地点取到了包裹。
在本例中:
1.数据块
10个取件地点就相当于数据块,快递员要取到包裹,需要抵达取件地点,SQL要查询到目标数据,需要扫描数据块(实际上SQL查询时,从数据块中读取到的数据可能还需要经过筛选条件过滤);
2.目标数据
100个包裹就相当于SQL查询的目标数据;
3.需要扫描的数据块
从出发到取完所有的包裹,期间的油耗就相当于扫描过的数据块。
问题:
1.路程长短
不难理解,如果路线规划得不好,显然会绕路,走过的路程就会越长,油耗就会越高;
2.取货顺序
如果快递员抵达的第一个收件点有91个又重又大的包裹,剩余的9个收件地点都只有一个又轻又小的包裹,那么就算他规划的路线再优,走过的路程是最短的,也不见得是一个最佳的结果,因为托着那么多的包裹走这么一段路,油耗反而可能变高了。
所以,SQL性能优化,就类似本例中“如何达到最低的油耗”的规划,不仅仅要考虑路程长短,还得根据包裹的分布情况考虑取货顺序。
上述例子只是为了帮助读者对SQL性能问题有个感性的认识,可能并不那么贴切,SQL性能问题要复杂得多。要真正理解SQL性能问题,我们至少需要掌握以下几个知识点:
1.数据(表、索引)存储结构(表、索引是如何存储的)
2.SQL执行原理(一段SQL在执行期间,究竟干了什么事情)
3.执行计划(告诉SQL查询程序从哪张表开始扫描,然后按什么顺序以什么关联方式关联下一张表,每张表是走索引还是走全表扫描,走索引的时候该怎么走,数据是否需要去重/汇总等等)
4.优化器(生成多个执行计划,并从中选择优化器认为成本最低的执行计划)
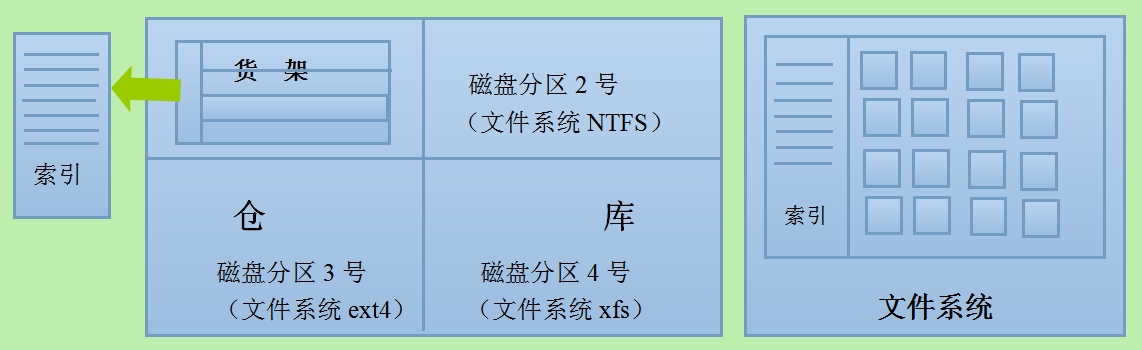
表、索引的逻辑存储结构
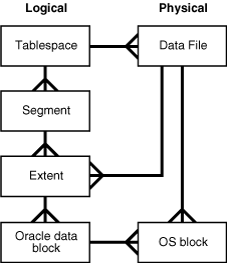
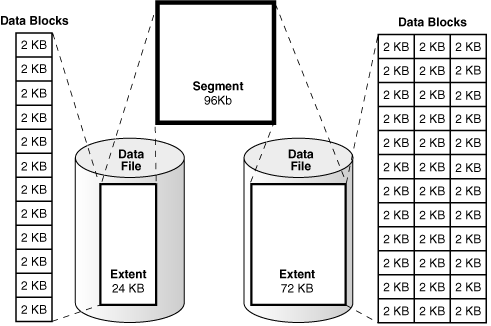
当某张表中新增数据时,会发生什么事情:
1.数据根据数据内容的大小,申请若干逻辑上连序的数据块用于存储数据,这部分连序的数据块就是“区”(Extent,逻辑上连序数据块)
2.数据最终以数据块(Data block)的形式存储到磁盘上(数据块是最小的存储单位)
3.表新增数据时,对应的索引也会新增数据,表和索引都各自以“段”(Segment)为逻辑单位进行存储(不考虑分区的情况,一张表为一个段,一个索引也为一个段),申请新的区用于存储新数据时,这些区也是分别隶属于表段和索引段中。
4.段只能隶属于一个表空间(Tablespace),但表和索引可以存储在不同的表空间中,随着表空间内容的增长,表空间的内容会存储到新的数据文件中。
结合上面两张图,我们不难想象,表、索引中包含的成千上万的数据,最终都以数据块(类似小方格)的形式存储在磁盘上。
由于每张表字段的数量、内容都不尽相同,同样的行数,在不同的表中会对应不同数量的数据块;但数据块相同,数据量(以磁盘空间大小为计量单位)的大小基本就是相同的。
所以在了解到这些知识之后,我们在分析SQL性能问题(执行计划)时,应该对这两个重要的指标有一个感性的认识:数据块和行数。
详细信息可参考官方文档:
Logical Storage Structures(逻辑存储结构)
#CNCPT004
SQL执行原理
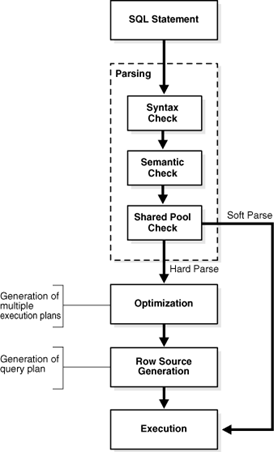
上图来自Oracle官网,展示了SQL的执行机制,总结、精简下来就是:
1.客户端提交sql语句
2.解析(语法检查、语义检查、共享池检查(确认这个sql是否有现成的解析结果,如果有则不再解析,即是软解析;否则走完整解析,即是硬解析))
3.sql改写优化(优化器尝试对sql进行等价的优化改写)
4.生成执行计划
5.执行sql(数据扫描并筛选、返回数据、数据传送到客户端)
详细信息可参考官方文档:
SQL Processing(SQL处理机制)
#TGSQL175
执行计划差异带来的性能差别
跟SQL性能优化相关度最高的就是SQL执行步骤4,执行计划的生成。执行计划的差异,至少直接决定了以下差异:
1.访问表时是走表扫描还是索引
2.表的关联顺序
3.表间关联方式/索引访问方式
而这些差异,结合之前快递员的例子,不难理解,会造成数据块扫描数量的差异。
扫描数据块数量的差异,本质上又决定了SQL查询性能的差异。
以下是表关联顺序带来性能差异的例子。
这张图中体现的关联顺序为: ( MIC_U1索引& MCB) à MSIB à MMT
这张图中体现的关联顺序为:MMTàMSIBà( MIC_U1索引& MCB)
注意两个执行计划中,最顶层返回的行数都是491:
第一个执行计划一开始就返回了较高的行数,直到MMT表才降到了万级的水平,耗时87秒左右;
第二个执行计划一开始到最后返回的行数都保持在千级的水平,耗时2.4秒左右。
上面都是表面效果的差别,以下用两张图来体现关联顺序差异下oracle优化,扫描数据块差异的差别:


上面两张图是sql优化前后区别的示意图,这里用方框的面积表示扫描的数据块数量:
1.最内部的浅色方框是我们最终得到的数据,注意上下两张图最里面的方框面积是一样的(其实是近似一样,画图水平有限,见谅)
2.不同颜色的方框,都代表了当前操作得到的一个结果集
3.不难理解,驱动表不一样,每个步骤得到的结果集的数量都不一样
4.在最终结果集数量一样的情况下,之前得到的结果集数量越多,说明扫描的数据块越多,自然耗时也会更长
表扫描和索引扫描的差异
不是所有的情况下,走索引一定是最优的。
扫描了索引之后,还要根据从索引上得到的rowid去访问表。走索引是否可以提高性能,本质上还是要看扫描索引和根据rowid访问表所扫描到的数据块数量较多,还是看全表扫描所扫描到的数据块数量较多。
两种访问方式哪种较优,跟我们需要访问的数据量占整表比例、索引大小、索引选择率有关。
以下两张图是用EXCEL画的,用于模拟SQL查询目标数据在索引和表上的分布情况。其中,一个单元格代表一个数据块,浅蓝色的单元格表示符合条件的数据。
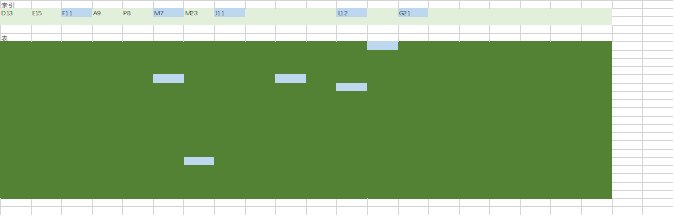

上图一走索引扫描,显然只需要扫描占比很少的数据块即可获取到所有目标数据;上图二走索引扫描,扫描了一遍索引之后,再去扫描表,前后加起来所扫描的数据库比全表扫描还多,显然这种情况走索引,效率还不如全表扫描。
图二的这种情况,我们称之为“选择率太低”,走这个索引能过滤掉的数据太少。
限于时间和篇幅,这里就不再做具体的例子。
BUFFER CACHE
而SQL执行的步骤5(数据块扫描),又存在从缓存读取数据和从磁盘读取数据两种情况。
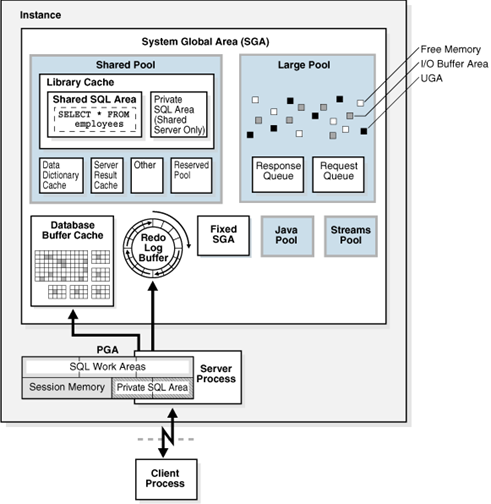
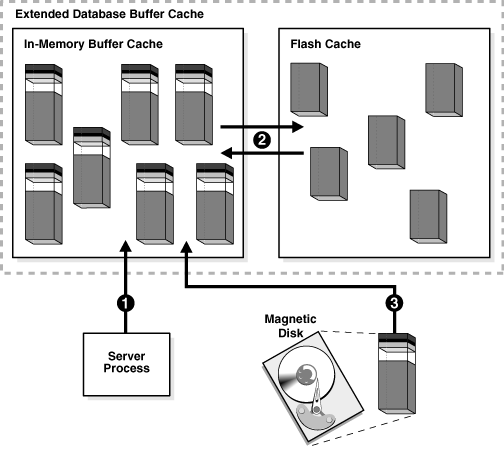
这里的缓存又叫“BUFFERCACHE”,实际就是一块内存区域(可参考上面两张图),其读取性能跟磁盘读取性能的差异,自然不用多说了,这里要说明的是BUFFER CACHE的机制:
1.为了解决磁盘读写效率的问题,数据库在内存开辟了一块区域,用来存储频繁读写的数据,以提高查询、更新数据的性能;
2.内存中这些发生变更的数据,由databasewriter (DBW)进程定期保存到磁盘中,相应的,磁盘上频繁读取、更新的数据,也会被加载到BUFFER CACHE中。
了解到BUFFER CACHE的机制之后,就不难理解有些SQL、报表程序在多运行几次几次之后变得快了很多这种现象了,因为这些要读取的数据经过频繁访问之后,已经由磁盘加载到了缓存中。
详细信息可参考官方文档:
Database Buffer Cache
#CNCPT1222
执行计划
简单的说,执行计划,就是告诉SQL查询程序从哪张表开始扫描,然后按什么顺序以什么关联方式关联下一张表,每张表是走索引还是走全表扫描,走索引的时候该怎么走,数据是否需要去重/汇总等等。
本文不讨论如何分析、理解执行计划,这里仅通过一个实例,让读者对执行计划有一个初步的印象和概念。
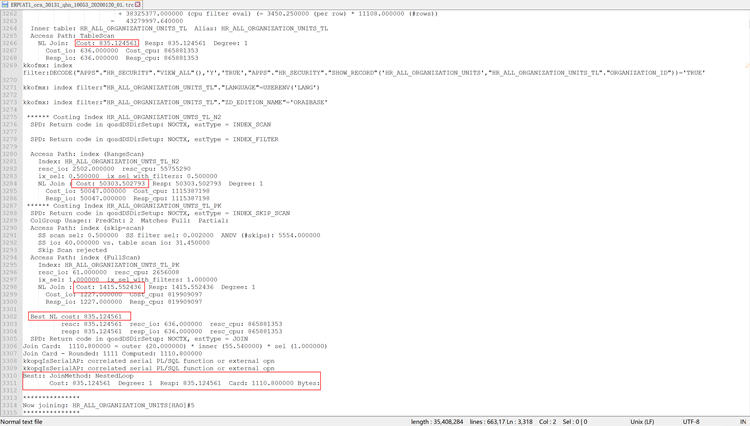
上图是一个SQL TRACE文件的截图,接下来我们对这个文件内容和执行计划做一个简单的分析:
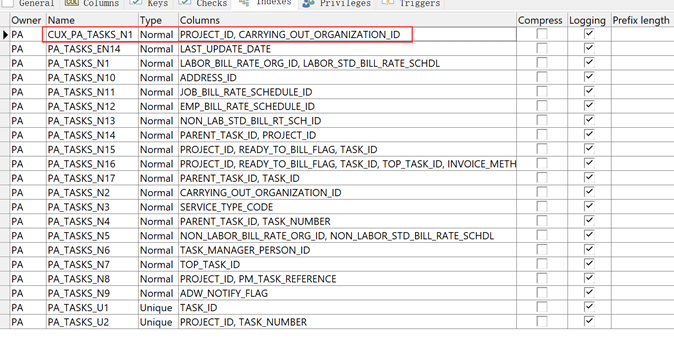
1.根据WHERE条件中的两个参数“PT.PROJECT_ID = :B2 ANDPT.CARRYING_OUT_ORGANIZATION_ID = :B1”,对索引CUX_PA_TASKS_N1进行扫描
2.扫描CUX_PA_TASKS_N1索引之后,得到一个符合条件的rowid结果集,以“INDEX ROWID BATCHED”的方式去访问PA_TASKS表。
为什么要去访问表?因为SELECT的字段里有TASK_NUMBER字段,WHERE条件里引用了TASK_ID字段,CUX_PA_TASKS_N1索引上并没有这些字段,要获取这些字段的值,就需要离开索引,到表本身走一遭。
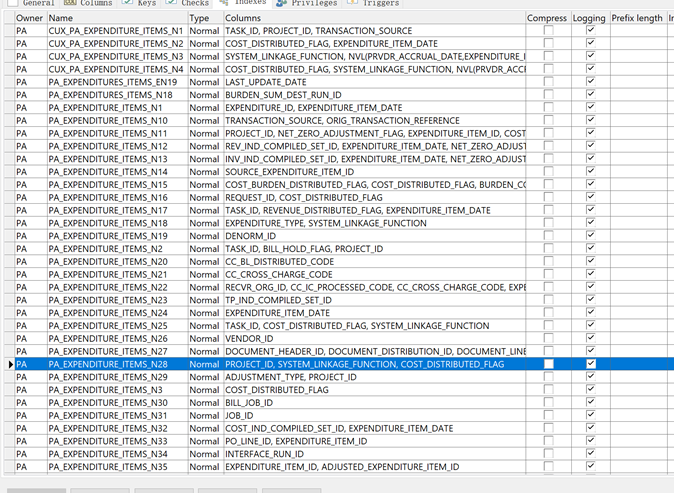
3.根据WHERE条件“PT.PROJECT_ID = PEI.PROJECT_ID ANDPT.TASK_ID = PEI.TASK_ID”,对PEI表的索引PA_EXPENDITURE_ITEMS_N28进行扫描。
4.扫描索引PA_EXPENDITURE_ITEMS_N28索引之后,得到的结果集于PT表进行HASH JOIN关联;
因为SELECT语句中引用到了EXPENDITURE_TYPE字段,WHERE条件引用到了EXPENDITURE_ITEM_ID字段,且索引上没有,于是又发起了对PEI表的访问。
5.对PEI表进行访问之后,就得到了EXPENDITURE_ITEM_ID信息,根据WHERE条件”PCDL.EXPENDITURE_ITEM_ID =PEI.EXPENDITURE_ITEM_ID”,对PCDL的索引PA_COST_DISTRIBUTION_LINES_U1发起了NESTED LOOPS关联扫描(虽然这是一个唯一性索引,但关联条件只给了其中一个字段,所以只能进行范围扫描)
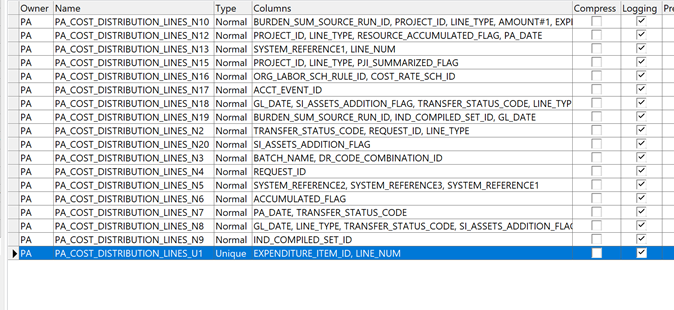
6.扫描索引PA_COST_DISTRIBUTION_LINES_U1之后,基于得到的rowid结果集对PCDL表发起NESTED LOOPS关联扫描(访问),当然,还是因为引用到了索引上没有的字段。
详细信息可参考官方文档:
Reading Execution Plans(执行计划阅读)
#TGSQL94618
优化器(选择执行计划)
简单的理解,优化器的作用就是生成(选择)执行计划。
执行计划的生成
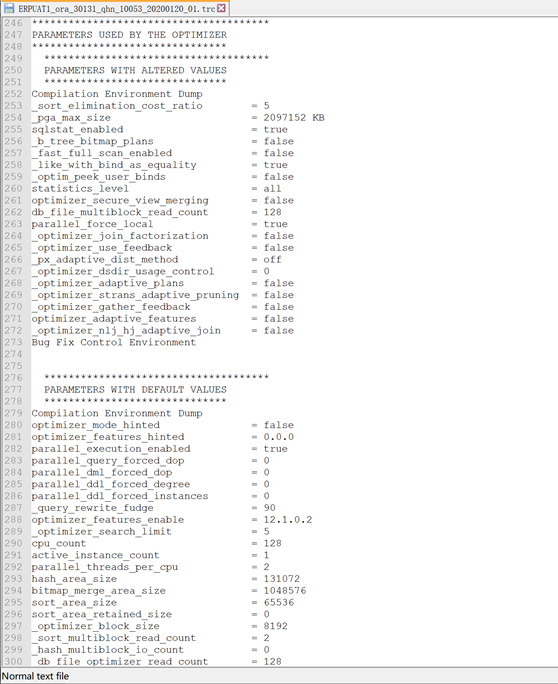
根据对10053事件TRACE的分析,得到执行计划生成的关键逻辑:
1.分析数据库参数(这些参数决定了优化器)
2.分析SQL中每一张表的统计信息
3.基于各种规则(Consideringcardinality-based initial join order、Considering RBO-ranked initial join order、Considering join cardinality basedinitial join order等等)生成关联顺序(生成很多不同关联顺序的执行计划,但最终还是COST最低的执行计划)
4.穷举关联下一张表的方式(表扫描、索引),并计算出对应的COST,最终选择COST最低的关联方式
(这里的逻辑和上述的几张截图按顺序对应)
从下图的Trace文件大小可以看到,虽然SQL查询瞬间就开始扫描数据,但在确定执行计划期间还是做了许多判断和选择:
如上图,优化器在此刻已经生成了500个以上的关联顺序(后续还有更多)。
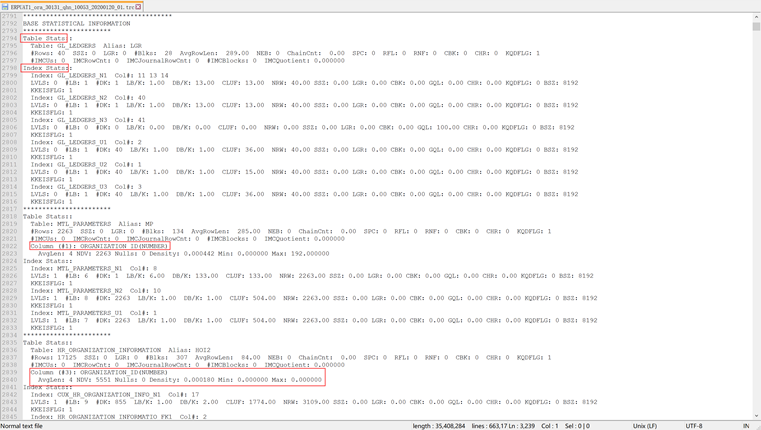
统计信息
10053事件TRACE中可以看到,统计信息对于执行计划的优劣有着至关重要的参考意义,所以统计信息一定要准确,否则优化器容易会“看走眼”,选择到一个错误的执行计划。
基于数据块的扫描数量评估SQL性能
以下通过SQL Plus工具下Auto trace的功能来做一些示例,说明一些问题。
这里先解释一下我们要关注的输出结果指标:
1.consistent gets
通过一致性读扫描的数据块数目,可以简单的理解为“查询这些数据需要扫描的数据库数量”(后面称之为“逻辑读”)
2.physical reads
通过物理读扫描的数据块数目,可以简单的理解为“需要的数据不在缓存中,需要从磁盘中读取的数据块数量”
3.rows processed
SQL语句处理过的行数,相当于SQL%ROWCOUNT
在sqlplus下开启“traceonly statistics”(仅显示统计信息,不显示sql查询结果),进行以下测试。
物理读
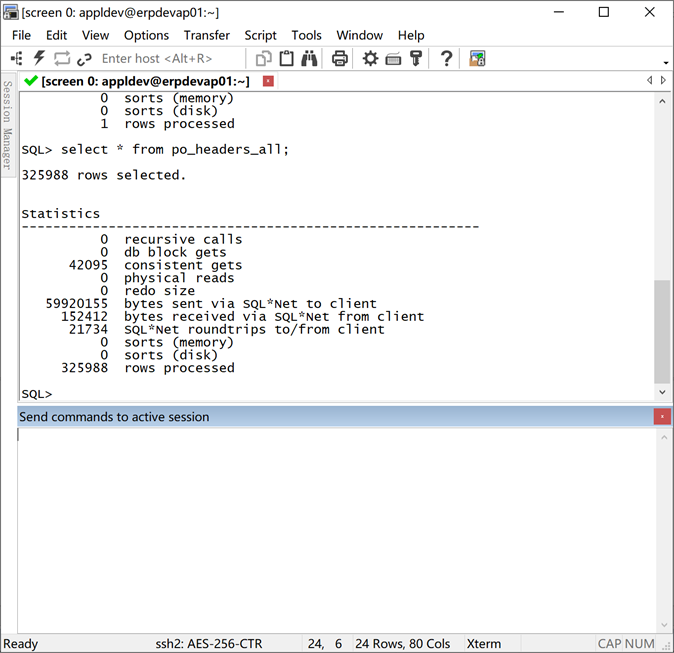
物理读消失,说明部分数据被缓存到BUFFERCACHE中了,如果大量物理读消失,SQL性能会有显著提升(但这个不是SQL性能优化的目标)。
全表扫描和索引扫描
全表扫描
索引扫描
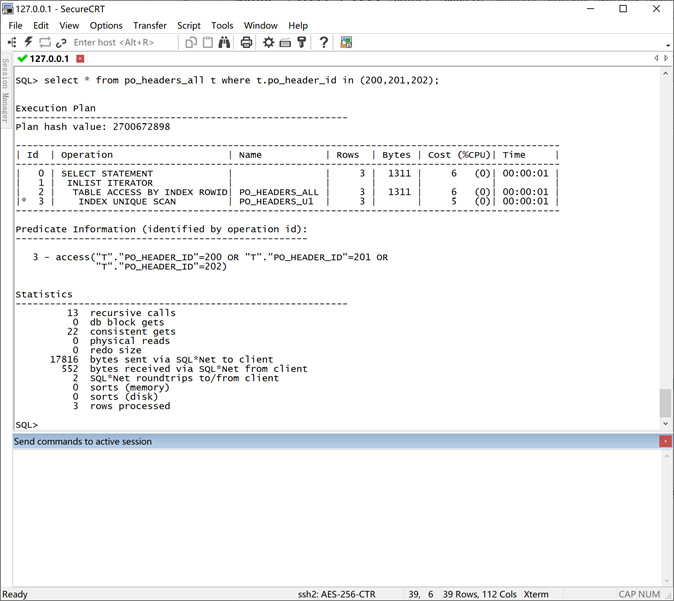
不同索引直接的差别
以下查询的都是同样3条的数据,只是条件和对应的索引不一样。
收集信息
当性能问题被提出时,我们需要收集信息定位问题。性能问题可能有以下几种场景:
1.某个报表跑得很慢,经常需要几小时甚至几天才能跑完;
2.某个程序长时间运行未能完成,停在了某段查询SQL的执行上;
3.某个界面在进行某个操作时,响应比较慢;
4.程序开发时,SQL刚写好,测试时发现性能不理想。
针对特定SQL进行性能优化时,我们针对该SQL收集相关的执行计划即可;针对整个程序进行全面性能优化时,我们需要对程序开启SQL跟踪(又叫TRACE、10046事件),收集程序运行期间所有SQL的执行计划,并针对性能较差SQL进行优化处理。
根据问题的实际情况,可能可能需要收集的信息有:
1.执行计划
2.直方图(反映某张表某个字段的内容分布情况)
3.AWR(记录系统运行性能状况的报告)
4.10053事件TRACE(这个TRACE记录了当前的执行计划是如何被选中的)
5.其他信息
大部分情况下,收集执行计划足矣。其他信息都是用于辅助判断类似“为什么选择全表扫描而不选择索引”、“为何出现这个等待事件”、“为何出现XXX现象”等等这样的问题,只有问题较为复杂时,才需要收集更多的信息。
常见收集执行计划的方式有:
1.使用DBMS_XPLAN程序包(从一些视图中抓取历史执行计划,有可能出现取不到的情况)
2.SQL Monitor(可以监控特定会话正在运行的SQL的执行情况,包括执行计划和当前的执行步骤,即停留在哪张表、哪个索引上)
3.使用“ALTER SESSION”命令开启SQL TRACE/10046事件,然后收集对应的TRACE文件
4.系统设置(针对EBS系统)
各类工具的使用,这里来不及整理了,以下简单列举一下EBS系统中常见获取SQL Trace文件的方式。
EBS并发请求
开启跟踪
提交请求之前,在并发程序定义界面开启跟踪。
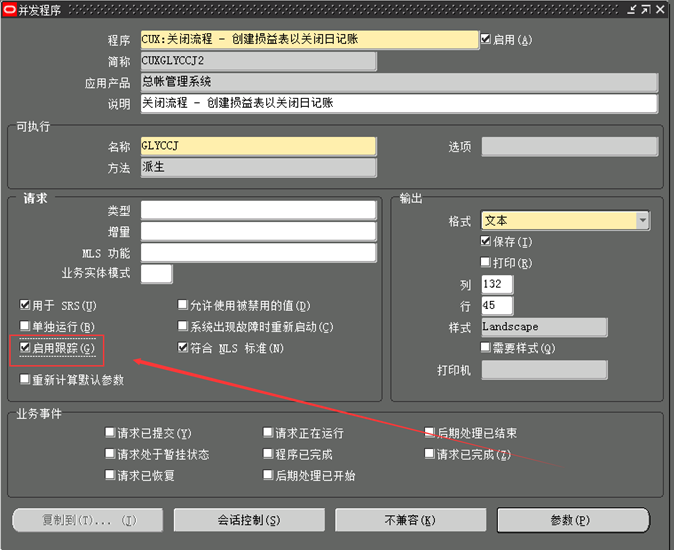
请求运行完成之后,就可以获取trace文件进行分析了。
获取请求trace文件路径
请求正在运行时,可以使用以下sql获取trace文件:

也可以使用以下sql获取请求trace文件:

表单界面
开启跟踪
操作之前,打开跟踪
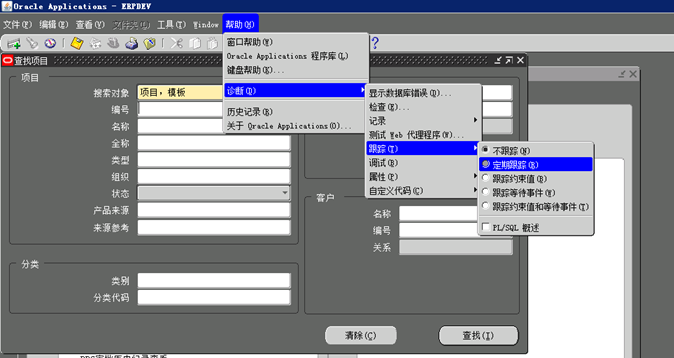
关闭跟踪
操作完成之后,关闭跟踪,避免收集过多的跟踪信息,影响分析。
获取trace文件&分析
这里就不展开说明如何分析了。
分析问题
这里暂时简单总结一下如何分析性能问题。
SQL Trace
分析SQL Trace文件时,我个人的思路主要是“枪打出头鸟”、“逐个击破”。优先级如下:
1.优先分析处理指标靠前的SQL、执行计划步骤(可能是耗时最长、逻辑读太高、物理读太高)
2.分析问题原因:索引是否高效、关联方式是否合理、表关联顺序是否合理
3.分析等待事件:是否存在IO等待(可能是磁盘性能问题)、Latch争用(可能是热块问题)、Library cache冲突(可能是并发硬解析)
SQL Monitor
SQL Monitor的输出跟DBMS_XPLAN类似,都带有每个步骤的指标,例如预估行数、实际行数、PGA内存占用等等。
如果实际行数和预估行数差别太大,考虑收集执行计划,如果SQL太复杂,考虑加hint;
如果某个步骤内存占用过高oracle优化,考虑关联条件是否合理,HASH JOIN是否可以改成NESTED LOOP关联等等。
DBMS_XPLAN
和SQL Monitor类似,略。
优化思路&手段
对SQL进行优化时,我们的实际操作都是为了帮助优化器选取最理想的执行计划。
以下列举一些常见的比较简单的场景。
统计信息过旧
统计信息过旧,会导致优化器无法作出正确的评估和判断,选择错误的执行计划。
此类问题只需要收集统计信息即可。
SQL太复杂
写得很复杂的SQL,优化器可能也很难作出准确的评估,需要使用hint来帮助优化器作出准确的选择。
谓词越界
传入的参数,例如日期超出了统计信息中的最大、最小值,也会导致优化器无法作出准确的选择。
参数太多
传入的参数太多,且这些参数可能关联到不同的表上,且每次传入的参数都不一样,在参数字段上存在很多NVL操作,优化器也是很难选取理想的执行计划。
此类情况一般是考虑使用动态语句,根据实际传入的参数做WHERE条件拼接。
表、索引碎片
如果表、索引的碎片化太严重,也会导致扫描的数据块过多,进而导致性能下降。
这种问题可以通过碎片整理解决。
业务优化
另外,对于EBS系统SQL的优化,不少案例也是通过业务优化(配合业务方案变更,改写SQL,减少处理的数据量)来实现。
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: wxii2p22




