

我坐在面试官的对面,声情并茂的做着自我介绍,面试官小哥哥面无表情的翻看着我的简历。不知道是小哥哥过于高冷还是被我的简历吸引,2分钟了,小哥哥还是没有和我讲一句话。嘤嘤嘤~看起来似乎有两下子。不过无所谓,这些都不重要。
什么是索引?
面试官:我看你项目中有做过 SQL 优化,那我们今天就来聊聊索引吧。
(索引能问些啥,无非是索引的概念、索引的使用规则、索引的分类、索引的原理。嘻嘻~我早有准备)

我:数据库中的索引,简单来说呐,就好比一本书的目录,它可以帮我们快速进行特定值的定位与查找,从而加快数据查询的效率。
如果我们不使用索引,就必须从第 1 条记录开始依次往后查找,直到把所有的数据表都查找完,才能找到想要的数据。
面试官:那照你这么说,索引是不是越多越好?
索引是不是越多越好?
我:当然索引也不是越多越好,索引也不是万能的,在有些情况下使用索引反而会让效率变低。
索引的价值是帮我们从海量数据中找到想要的数据,如果数据量少,那么是否使用索引对结果的影响并不大。
在数据表中的数据行数比较少的情况下,比如不到 1000 行,是不需要创建索引的。另外,当数据重复度大,比如高于 10% 的时候,也不需要对这个字段使用索引。
比如,如果是性别这个字段,就不需要对它创建索引。这是为什么呢?如果你想要在 100 万行数据中查找其中的 50 万行(比如性别为男的数据),一旦创建了索引,你需要先访问 50 万次索引,然后再访问 50 万次数据表,这样加起来的开销比不使用索引可能还要大。
索引的种类
面试官点点头,看起来对我以上的回答还算满意。接着又问:
面试官:那你说说索引有哪些种类?
(嘻嘻,对于索引的种类我太熟了。但我还是稍稍顿了顿开始了我的回答。)

按照功能逻辑分类
我:从功能逻辑上说,索引主要有 4 种,分别是普通索引、唯一索引、主键索引和全文索引。
普通索引是基础的索引,没有任何约束,主要用于提高查询效率。
唯一索引就是在普通索引的基础上增加了数据唯一性的约束,在一张数据表里可以有多个唯一索引。
主键索引在唯一索引的基础上增加了不为空的约束,也就是 NOT NULL+UNIQUE,一张表里最多只有一个主键索引。
全文索引用的不多,MySQL 自带的全文索引只支持英文。我们通常可以采用专门的全文搜索引擎,比如 ES(ElasticSearch) 和 Solr。
其实前三种索引(普通索引、唯一索引和主键索引)都是一类索引,只不过对数据的约束性逐渐提升。
在一张数据表中只能有一个主键索引,这是由主键索引的物理实现方式决定的,因为数据存储在文件中只能按照一种顺序进行存储。但可以有多个普通索引或者多个唯一索引。

按照物理实现方式分类
我:按照物理实现方式,索引可以分为 2 种:聚集索引和非聚集索引。我们也把非聚集索引称为二级索引或者辅助索引。
聚集索引可以按照主键来排序存储数据,这样在查找行的时候非常有效。
举个例子,如果是一本汉语字典,我们想要查找“数”这个字,直接在书中找汉语拼音的位置即可,也就是拼音“shu”。这样找到了索引的位置,在它后面就是我们想要找的数据行。
非聚集索引不会把索引指向的内容像聚集索引一样直接放到索引的后面,而是维护单独的索引表(只维护索引,不维护索引指向的数据),为数据检索提供方便。
我们还以汉语字典为例,如果想要查找“数”字,那么按照部首查找的方式,先找到“数”字的偏旁部首,然后这个目录会告诉我们“数”字存放到第多少页,我们再去指定的页码找这个字。
也就是说系统会进行两次查找,第一次先找到索引,第二次找到索引对应的位置取出数据行。
聚集索引和非聚集索引二者的区别
其实回答到上面已经可以了,但是为了展示自己理解的透彻,我还做了以下阐述:
我:聚集索引与非聚集索引的原理不同,在使用上也有一些区别:
聚集索引的叶子节点存储的就是我们的数据记录,非聚集索引的叶子节点存储的是数据位置。非聚集索引不会影响数据表的物理存储顺序。一个表只能有一个聚集索引,因为只能有一种排序存储的方式,但可以有多个非聚集索引,也就是多个索引目录提供数据检索。使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。索引的数据结构
面试官:你刚才从功能逻辑和物理实现的方式阐述了索引的分类,看来对索引的数据结构是有了解的,说一说你知道的索引数据结构就有哪些。
(这个简单啊,我脱口而出)
我:Hash、B 树和 B+ 树都可以作为索引的数据结构,但是在 MySQL 中采用的是 B+ 树,B+ 树也是我们常用的索引数据结构。
为什么我们常用 B+ 树作为索引的数据结构?
面试官:为什么我们常用 B+ 树作为索引的数据结构?其它树形结构不香吗?
(我就知道没那么简单。唉,我刚才为什么要提“常用”俩字呢?我内心哭笑不得,但还是强作镇定。)

我:在回答这个问题之前我先说一下索引的存放位置,以及索引的数据结构设计好坏的评判标准。
索引的存放位置
我:我们知道,数据库服务器有两种存储介质,分别为硬盘和内存。内存属于临时存储,当发生意外时,比如说断电或者发生故障重启,会造成数据丢失;硬盘相当于永久存储介质,数据可持久化,这也是为什么我们需要把数据保存到硬盘上。
如何评价索引的数据结构设计好坏?
我:虽然内存的读取速度很快,但我们还是需要将索引存放到硬盘上。因此,当我们在硬盘上进行查询时,也就产生了硬盘的 I/O 操作。
我们都知道,硬盘的 I/O 存取消耗的时间相比于内存的存取来说,要高很多。我们通过索引来查找某行数据的时候,需要计算产生的磁盘 I/O 次数,当磁盘 I/O 次数越多,所消耗的时间也就越大。
如果我们能让索引的数据结构尽量减少硬盘的 I/O 操作,所消耗的时间也就越小,那么这个索引的数据结构设计的也就越优。
二叉树
面试官点点头示意我继续说下去,为了对“为什么我们常用 B+ 树作为索引的数据结构”这个问题进行一个小白都能看懂的满意回答,我拿起了笔,图文并茂的从二叉树开始和面试官扯了起来。

我:接下来说说二叉树,我们知道二分查找法是一种高效的数据检索方式,时间复杂度为 O(log2n),可以说检索速度是很快了。
以最基础的二叉搜索树(Binary Search Tree)为例,搜索某个节点和插入节点的规则一样,我们假设搜索插入的数值为 key:
如果 key 大于根节点,则在右子树中进行查找;如果 key 小于根节点,则在左子树中进行查找;如果 key 等于根节点,也就是找到了这个节点,返回根节点即可。
举个例子,我们对数列(25,18,36,9,20,32,41)创造出来的二分查找树如下图所示:
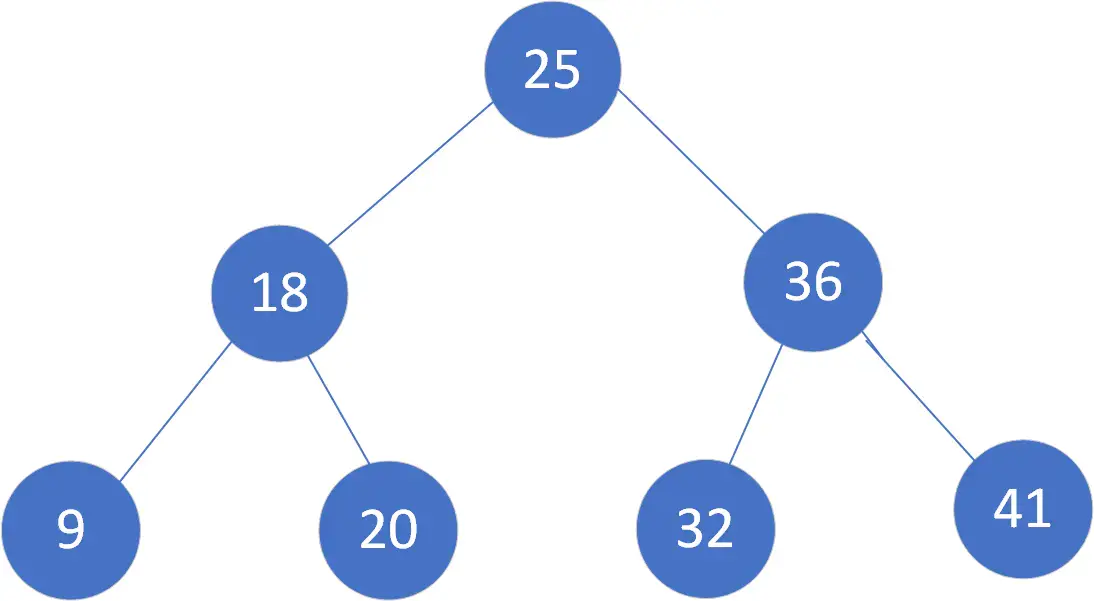
但是存在特殊的情况,二叉树的深度会非常大。比如我们给出的数据顺序是 (9, 18, 20, 25, 32, 36, 41),创造出来的二分搜索树如下图所示:
现在这棵树也属于二分查找树,但是性能上已经退化成了一条链表,查找数据的时间复杂度变成了 O(n)。
我们可以看出来第一个树的深度是 3,也就是说最多只需 3 次比较,就可以找到节点,而第二个树的深度是 7,最多需要 7 次比较才能找到节点。
平衡二叉搜索树
面试官:既然普通的二叉树不行,那平衡二叉搜索树怎么样?因为我们知道它可以通过旋转的方式避免数据结构在特殊情况下退化成链表。
我:我刚才提到过,数据查询的时间主要依赖于磁盘 I/O 的次数,即使是用了改进后的平衡二叉搜索树,树的深度也是 O(log2n),当 n 比较大时,深度也是比较高的,比如下图的情况:
每访问一次节点就需要进行一次磁盘 I/O 操作,对于上面的树来说,我们需要进行 5 次 I/O 操作。虽然平衡二叉树比较的效率高,但是树的深度也同样高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
什么是 B 树?
我:针对上面同样的数据,如果我们把二叉树改成 M 叉树(M>2)的话,当 M=3 时,同样的 31 个节点可以由下面的三叉树来进行存储:
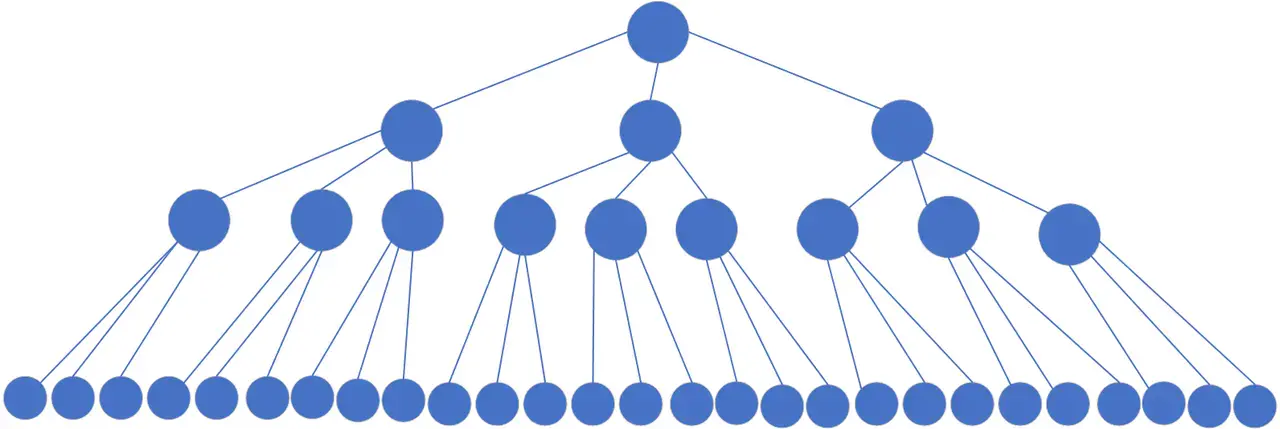
你能看到此时树的高度降低了,当数据量 N 大的时候,以及树的分叉数 M 大的时候,M 叉树的高度会远小于二叉树的高度。
如果用二叉树作为索引的实现结构,会让树变得很高,增加硬盘的 I/O 次数,影响数据查询的时间。因此一个节点就不能只有 2 个子节点,而应该允许有 M 个子节点 (M>2)。
而B 树的出现就是为了解决这个问题,B 树的英文是 Balance Tree,也就是平衡的多路搜索树,它的高度远小于平衡二叉树的高度。在文件系统和数据库系统中的索引结构经常采用 B 树来实现。
B 树的结构如下图所示:
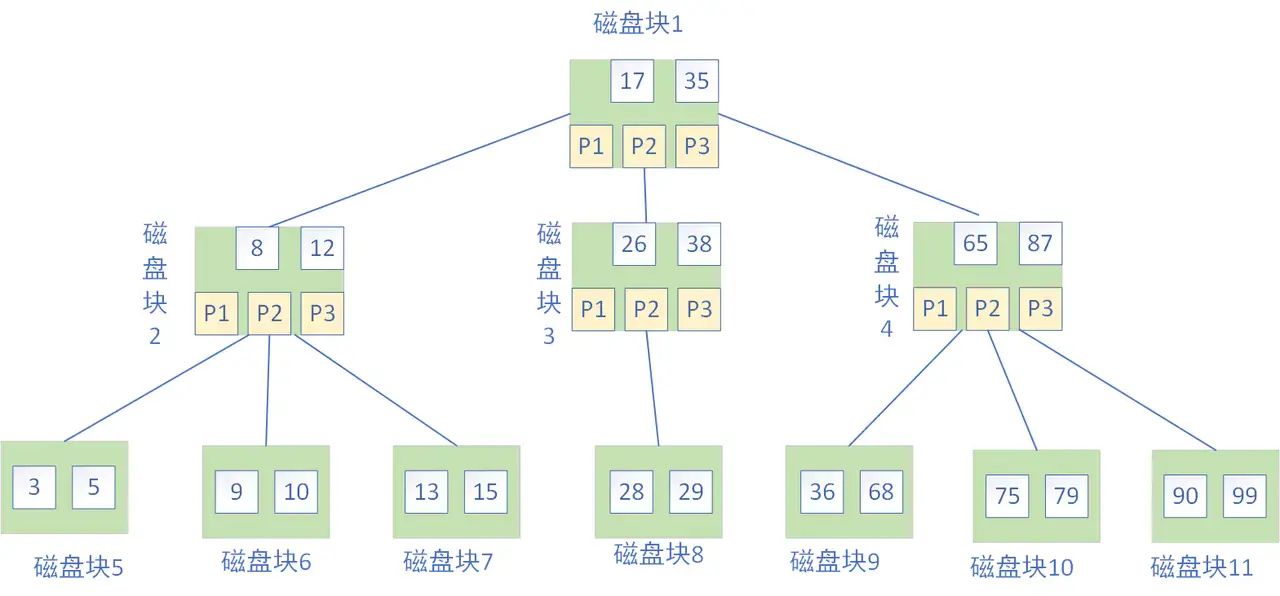
B 树作为平衡的多路搜索树,它的每一个节点最多可以包括 M 个子节点,M 称为 B 树的阶。同时你能看到,每个磁盘块中包括了关键字和子节点的指针。如果一个磁盘块中包括了 x 个关键字,那么指针数就是 x+1。对于一个 100 阶的 B 树来说,如果有 3 层的话最多可以存储约 100 万的索引数据。对于大量的索引数据来说,采用 B 树的结构是非常适合的,因为树的高度要远小于二叉树的高度。
一个 M 阶的 B 树(M>2)有以下的特性:
根节点的儿子数的范围是 [2,M]。每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为 [ceil(M/2), M]。叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i]所有叶子节点位于同一层。
上面那张图所表示的 B 树就是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它有 3 个孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15) 大于 12,刚好符合刚才我们给出的特征。
然后我们来看下如何用 B 树进行查找。假设我们想要查找的关键字是 9,那么步骤可以分为以下几步:
我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
我们可以看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比较,这个时间就是可以忽略不计的。
而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行比较所需要的时间要多,是数据查找用时的重要因素,B 树相比于平衡二叉树来说磁盘 I/O 操作要少,在数据查询中比平衡二叉树效率要高。
什么是 B+ 树?
我:在最后说说 B+ 树,B+ 树是基于 B 树做出了改进,主流的 DBMS 都支持 B+ 树的索引方式,比如 MySQL。B+ 树和 B 树的差异在于以下几点:
有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1。非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中,非叶子节点既保存索引,也保存数据记录。所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
下图就是一棵 B+ 树,阶数为 3,根节点中的关键字 1、18、35 分别是子节点(1,8,14),(18,24,31)和(35,41,53)中的最小值。每一层父节点的关键字都会出现在下一层的子节点的关键字中,因此在叶子节点中包括了所有的关键字信息,并且每一个叶子节点都有一个指向下一个节点的指针,这样就形成了一个链表。
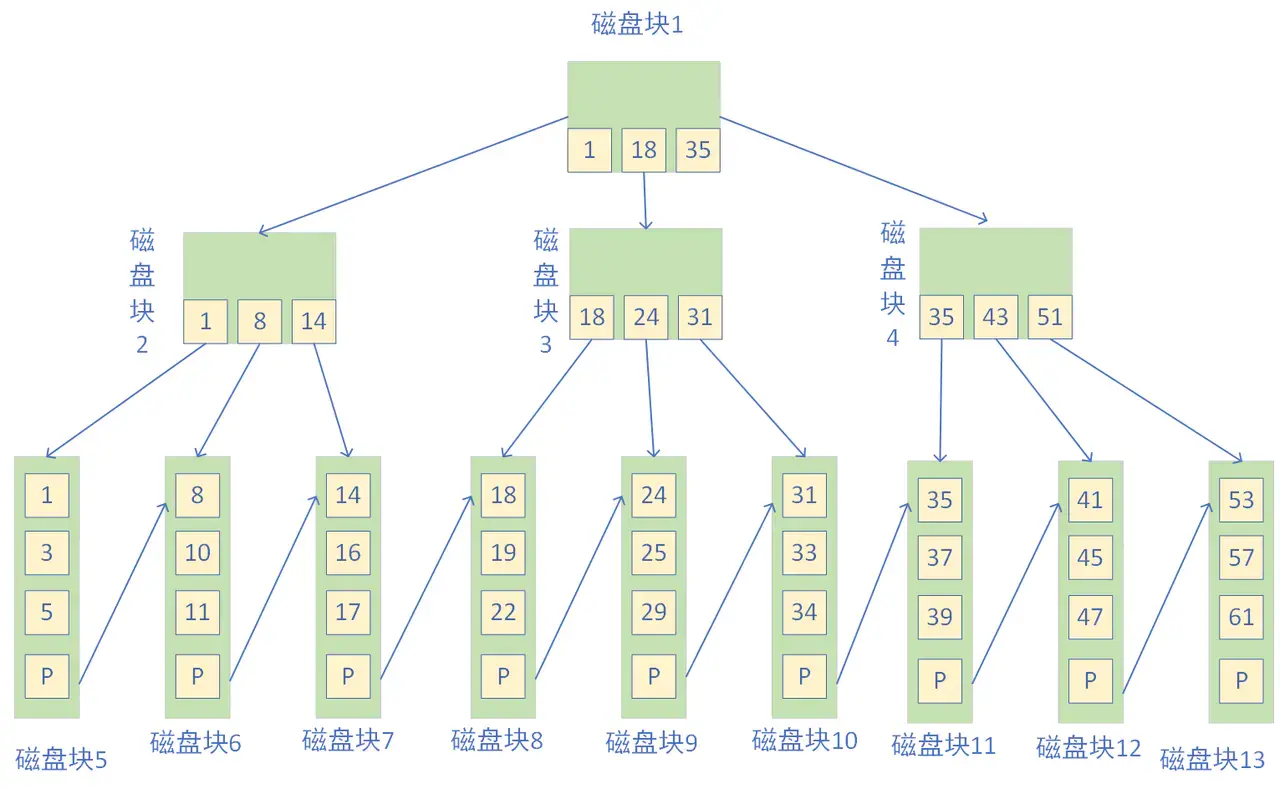
比如,我们想要查找关键字 16,B+ 树会自顶向下逐层进行查找:
与根节点的关键字 (1,18,35) 进行比较,16 在 1 和 18 之间,得到指针 P1(指向磁盘块 2)找到磁盘块 2,关键字为(1,8,14),因为 16 大于 14,所以得到指针 P3(指向磁盘块 7)找到磁盘块 7,关键字为(14,16,17),然后我们找到了关键字 16,所以可以找到关键字 16 所对应的数据。
面试官:B+ 树整个过程一共进行了 3 次 I/O 操作,看起来 B+ 树和 B 树的查询过程差不多,那为什么我们使用 B+ 树更多呢?
我:B+ 树和 B 树有个根本的差异在于,B+ 树的中间节点并不直接存储数据。这样的好处是:
不仅是对单个关键字的查询上,在查询范围上,B+ 树的效率也比 B 树高。这是因为所有关键字都出现在 B+ 树的叶子节点中,并通过有序链表进行了链接。而在 B 树中则需要通过中序遍历才能完成查询范围的查找,效率要低很多。
(说到这里我自己都满意的想哭,完了我还不忘了总结)

总的来说,磁盘的 I/O 操作次数对索引的使用效率至关重要。虽然传统的二叉树数据结构查找数据的效率高,但很容易增加磁盘 I/O 操作的次数,影响索引使用的效率。因此在构造索引的时候,我们更倾向于采用“矮胖”的数据结构。
B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树,B+ 树在查询性能上更稳定,在磁盘页大小相同的情况下,树的构造更加矮胖,所需要进行的磁盘 I/O 次数更少,更适合进行关键字的范围查询。
面试官拿起旁边已经凉透的咖啡,喝了一口。
(这小姑娘有点东西呀)
「持续更新……」

爱心三连
最后,感谢各位的阅读。文章的目的是记录和分享,若文中出现明显纰漏也欢迎指出,我们一起在探讨中学习。不胜感激 !
如果你觉得本文对你有用,那就给个「赞」吧,你的鼓励和支持是我前进路上的动力~
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: wxii2p22




