


在 QCon Plus 大会上,Juan Fumero 谈到了 TornadoVM,一种Java虚拟机(JVM)高性能计算平台。Java 开发人员可以通过它在 GPU、FPGA 或多核 CPU 上自动运行程序。
像 GPU 这样的异构设备几乎出现在现今的所有计算系统中。例如,移动设备配备了一个多核 CPU 和一个集成 GPU;笔记本电脑通常有两个 GPU,一个与主 CPU 集成,另一个有专门用途(通常用于游戏)。甚至连数据中心也在集成像 FPGA 这样的设备。因此,异构设备将会继续存在。
所有这些设备都有助于提升性能和运行更有效的工作负载。当前和未来计算系统的程序员需要在各种各样的计算设备上处理程序执行。但是,很多并行编程框架都是基于 C 和 C++,使用高级编程语言(如 Java)开发的这类系统几乎是不存在的。这就是为什么我们要推出 TornadoVM。
简单地说,TornadoVM 是一个针对 Java 和 JVM 的高性能计算编程平台,可以在运行时将 Java 代码加载到异构硬件加速器上运行。
TornadoVM 提供了一个 Parallel Loop API 和一个 Parallel Kernel API。在这篇文章中,我们将分别介绍它们,并提供一些性能测试基准,还将分享 TornadoVM 如何将 Java 代码转译成可在并行硬件上执行的机器码。最后,我们将介绍 TornadoVM 在行业中的应用情况,包括一些应用场景。
GPU 和 FPGA 的快速通道
现如今,高级编程语言是如何访问异构硬件的?下图展示了一些硬件(CPU、GPU、FPGA)和高级编程语言(如 Java、R 语言或 Python)的例子。
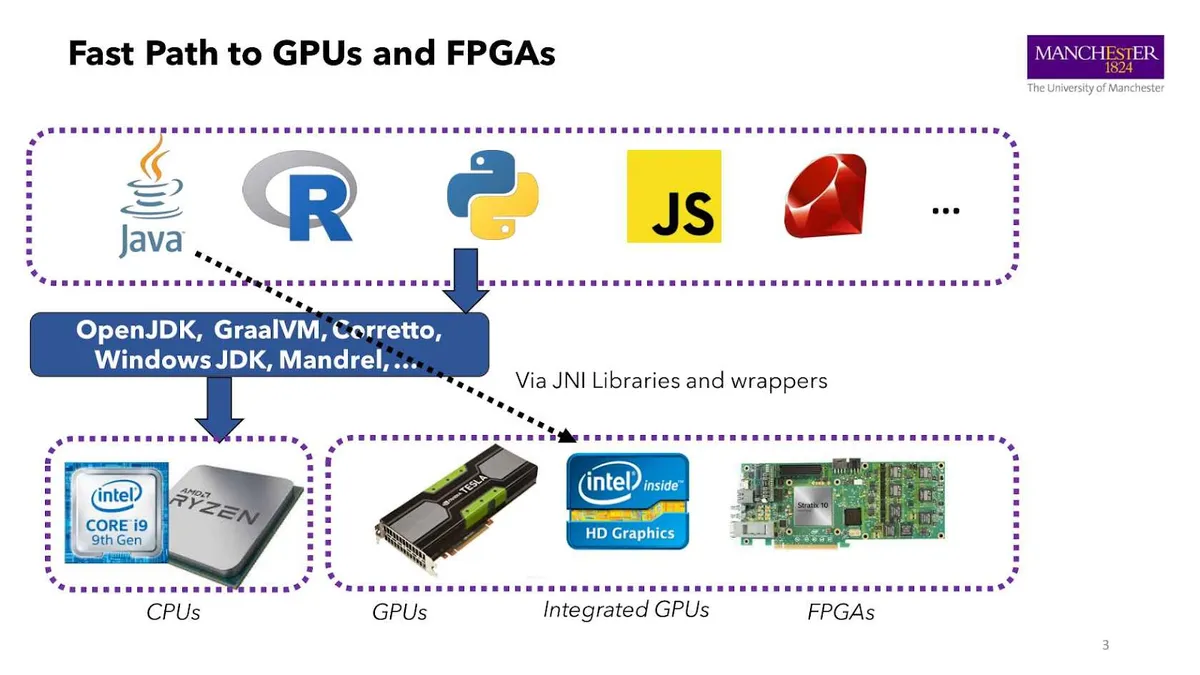
看一下 Java,我们会发现它是在虚拟机中运行的。其中,OpenJDK、GraalVM 和 Corretto 都是虚拟机(VM)实现。本质上,Java 源代码被编译成 Java 字节码,然后 VM 执行这些字节码。如果应用程序运行得很频繁,虚拟机可以通过将频繁执行的方法编译成机器码的方式来进行优化——但这仅针对 CPU。
如果开发人员想要访问异构设备,比如 GPU 或 FPGA,他们通常需要通过 Java 本地接口(JNI)库来实现。
程序员必须导入一个库,并通过 JNI 调用这个库。程序员可以通过使用这些库为特定的 GPU 优化应用程序。但如果应用程序或 GPU 发生变化,可能需要重新构建应用程序,或需要重新调整优化参数。类似地,对于不同的 FPGA 甚至是其他型号的 GPU 也是如此。
因此,没有一个完整的 JIT 编译器和运行时能够像 CPU 那样处理异构设备,检测频繁执行的代码,并生成优化的机器码。而 TornadoVM 就是为此而生的。
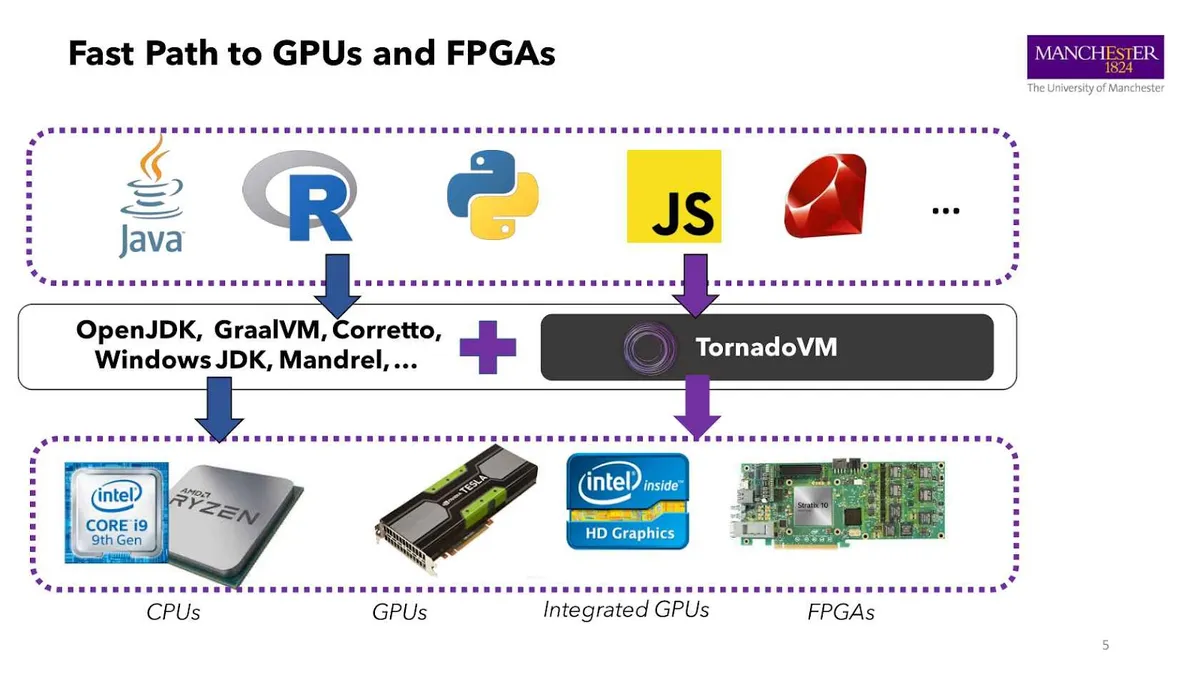
TornadoVM 可以与现有的 JDK 结合使用。它是 JDK 的一个插件,程序员可以借助它在异构硬件上运行应用程序。目前,TornadoVM 可以运行在多核 CPU、GPU 和 FPGA 上。
硬件特征和并行化
下一个问题是,为什么要支持这么多硬件?目前正在考虑支持三种不同的硬件架构:CPU、GPU 和 FPGA。每种架构都针对不同类型的工作负载进行了优化。
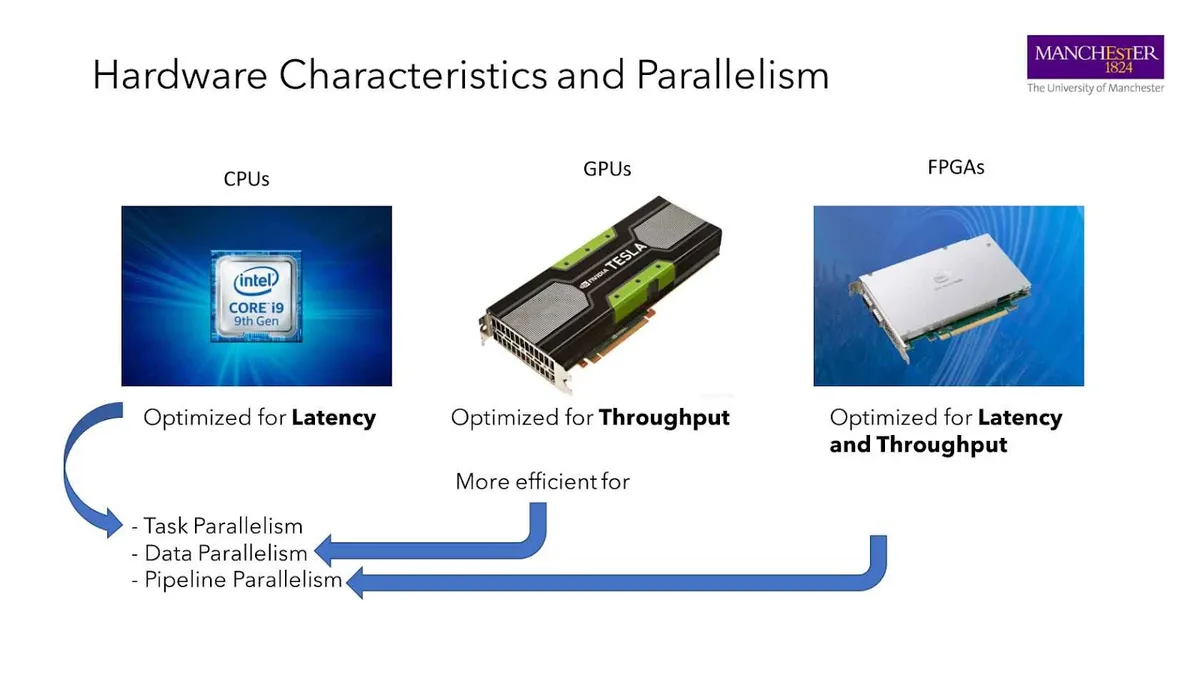
优化 CPU 是为了降低应用程序的延迟,优化 GPU 是为了提高吞吐量。FPGA 介于二者之间:由于应用程序被物理连接到硬件上,FPGA 通常可以实现较低的延迟和较高的吞吐量。
我们将这些架构与现有的并行化类型映射起来。在上图中,我们可以发现并行化主要有三种类型:任务并行化、数据并行化和管道并行化。
通常,CPU 是为任务并行化而优化的,这意味着每个内核可以运行不同且独立的任务。相比之下,GPU 是为运行并行数据而优化的,这意味着执行的函数和内核是相同的,但输入数据不一样。最后,FPGA 非常适用于管道并行化,即不同指令的执行在不同的内部阶段之间会重叠。
理想情况下,我们需要一个高级并行编程框架,可以它表达不同类型的并行性,从而最大化每种设备类型的性能。现在,让我们看看 TornadoVM 是如何构建的,以及开发人员如何用它来表达不同类型的并行性。
TornadoVM 概览
TornadoVM 是 JDK(Java 开发工具包)的插件,Java 开发人员可以用它在异构硬件上自动执行程序。TornadoVM 的主要特性如下:
它有一个优化的 JIT(Just In Time)编译器,会针对每一种架构优化代码。这意味着为 GPU 生成的代码不同于为 CPU 和 FPGA 生成的代码,从而最大化每种架构的性能。
TornadoVM 可以实现架构之间、设备之间的动态任务迁移。例如,它可以先在 GPU 上运行应用程序一段时间,然后根据需要将其迁移到另一个 GPU、FPGA 或多核 CPU 上,无需重新启动应用程序。
TornadoVM 是完全硬件无关的:在异构硬件上运行的应用程序源代码与在 GPU、CPU 和 FPGA 上运行的是一样的。
最后,它可以与多种 JDK 结合适用。它是开源的(可以在GitHub上获得),Docker 镜像也可以在 NVIDIA 和 Intel 集成 GPU 上运行。
TornadoVM 系统栈
让我们来看一下 TornadoVM 的系统栈。在顶层,TornadoVM 暴露了一个 API,这是因为虽然它要利用并行化,但不检测。因此,它需要一种方法来识别应用程序源代码中哪些地方使用了并行化。
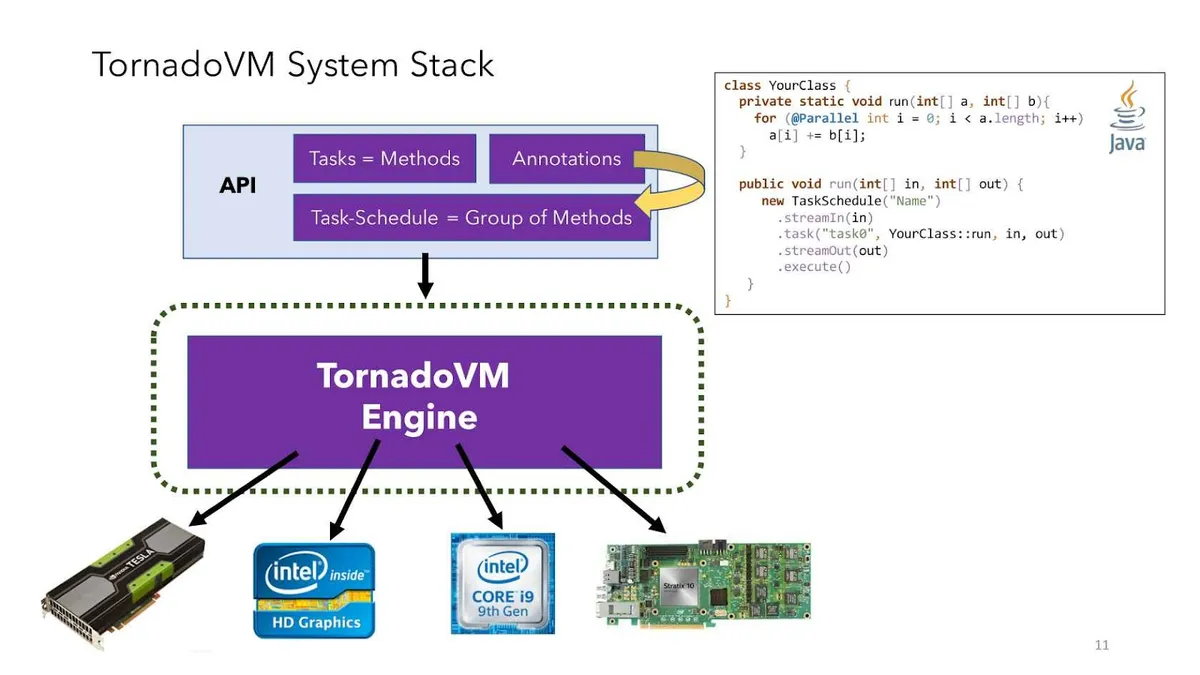
TornadoVM 提供了一个基于任务的编程 API,每个任务对应一个现有的 Java 方法。也就是说,TornadoVM 是在方法级编译代码,就像 JDK 或 JVM 那样,但编译的代码是面向 GPU 和 FPGA 的。我们也可以在方法中使用注解来指示并行化。另外,方法可以分成任务组,在同一个编译单元中进行编译。编译单元叫作 Task-Schedule: Task-Schedule 有一个名字(用于调试和优化),并包含了一组任务。
TornadoVM 引擎读入字节码级别的表达式,并自动为不同的架构生成代码。它目前有三个生成代码的后端,分别生成 OpenCL、CUDA 和 SPIR-V 代码。开发人员可以选择使用哪一个,或者让 TornadoVM 默认选择一个。
模糊滤镜示例
我们现在来看一个 TornadoVM 如何加速 Java 应用程序的例子:模糊滤镜。我们有一张图片,想要对这张图片应用模糊效果。
在了解如何编写代码之前,我们先来看看这个应用程序在异构硬件上运行的性能。下图显示了四种不同实现的测试基准。我们将 Java 的串行实现作为参考,y 轴是相对于参考的性能增益,越高表示性能越好。
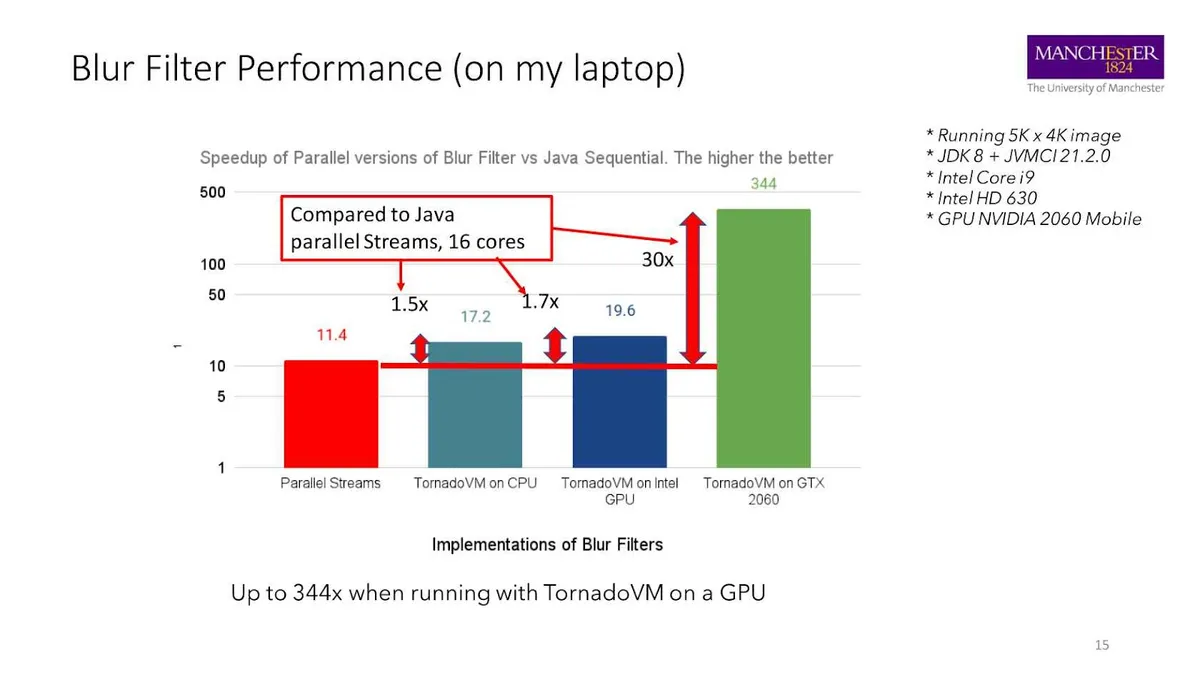
左边的两列表示基于 CPU 的执行结果。第一列使用标准的 Java 并行流,第二列使用运行在多 CPU 核心上的 TornadoVM,分别获得 11 倍和 17 倍的加速。TornadoVM 获得更好的结果,因为它为 CPU 生成了 OpenCL 代码,而 OpenCL 非常擅长使用向量单位对代码进行矢量化。如果应用程序在集成显卡上运行,与 Java 串行实现相比,可以获得 19 倍的性能加速。如果在 NVIDIA GPU(2060)上运行应用程序,可以获得高达 340x 的性能加速(使用 TornadoVM 的 OpenCL 后端)。我们将性能加速与 Java 并行流相比,当在 NVIDIA GPU 上运行时,TornadoVM 可以获得 30 倍的性能加速。
模糊滤镜的实现
模糊滤镜是一种映射操作符,将一个函数(模糊效果)应用在每一个输入的图像像素上。这种模式非常适合进行并行化,因为每个像素都可以独立于其他像素进行计算。
我们要做的第一件事是在 Java 方法中给代码添加注解,让 TornadoVM 知道如何并行化它们。

因为每一个像素的计算可以并行进行,所以我们将 @Parallel 注解添加到最外层的两个循环中。这将向 TornadoVM 发出信号,让它完全并行计算这两个循环。代码注解定义了数据并行化模式。
第二件事情是定义任务。由于输入的是 RGB 图像,我们可以为每个颜色通道(红、绿、蓝)创建一个任务。因此,我们要做的是对每个通道进行模糊处理。我们使用了一个包含三个任务的 TaskSchedule 对象。

此外,我们还需要定义哪些数据将从 Java 内存堆传输到设备(例如 GPU)上。这是因为 GPU 和 FPGA 通常不共享内存。因此,我们需要一种方法来告诉 TornadoVM 需要在设备之间复制哪些内存区域。这是通过 streamIn()和 streamOut()函数来完成的。
然后是定义任务集,每个颜色通道一个任务。它们有名字标识,并通过方法引用组合在一起。这个方法现在可以被编译成内核代码。
最后,我们调用 execute 函数,在设备上并行执行这些任务。现在我们来看看 TornadoVM 是如何编译和执行代码的。
TornadoVM 如何在并行硬件上启动 Java 内核
原始的 Java 代码是单线程的,即使已经加了 @Parallel 注解。在 execute()函数被调用时,TornadoVM 开始优化代码。
首先,代码被编译成一种中间表示,以便对其进行优化(TornadoVM 扩展了 Graal JIT 编译器,所有的优化都发生在这一层)。然后,TornadoVM 将优化后的代码转换成高效的 PTX、OpenCL 或 SPIR-V 代码。
这个时候开始执行代码,将会启动数百或数千个线程。TornadoVM 会启动多少个线程取决于应用程序。
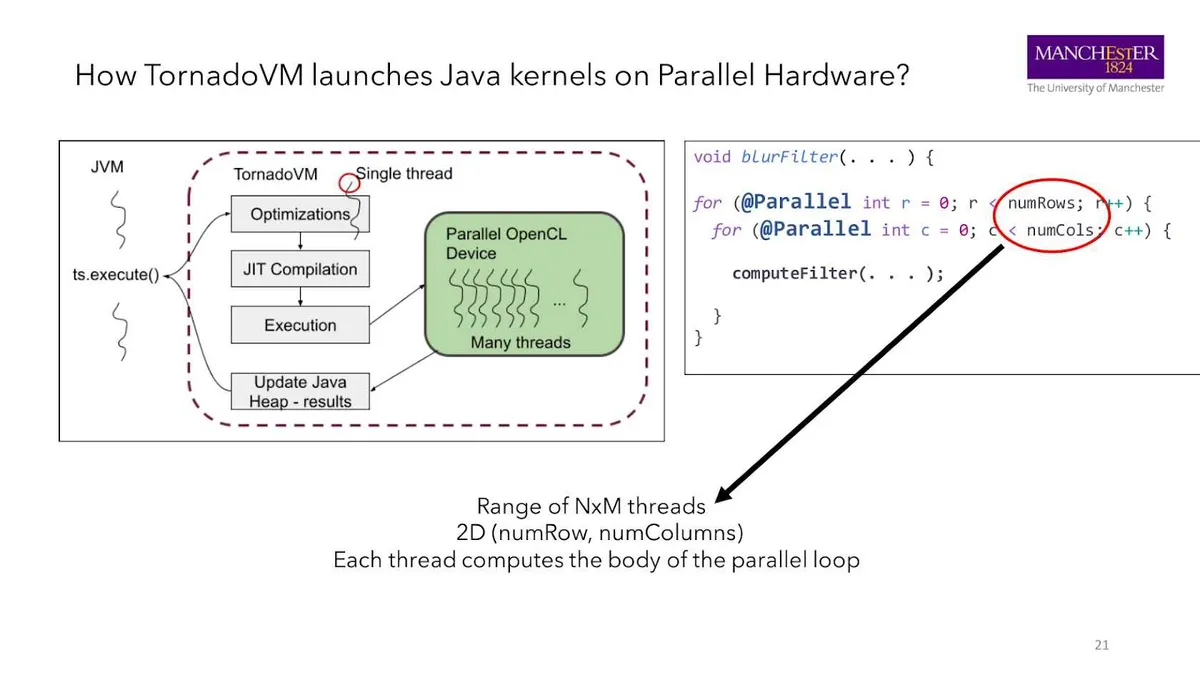
在这个例子中,模糊滤镜有两个并行循环,每个循环遍历一个图像维度。因此,在运行时编译期间,TornadoVM 创建了一个与输入图像具有相同维度的线程网格。每个网格单元(也就是每个像素)映射一个线程。例如,如果图像的像素是 2000×2000,TornadoVM 将在目标设备(例如 GPU)上启动 2000×2000 个线程。
TornadoVM 还可以实现管道并行化,主要是针对 FPGA。当我们或 TornadoVM 选择了 FPGA,它会自动将生成代码的信息插入到管道指令中。与之前的并行代码相比,这种策略可以将性能提高一倍。
Parallel Loop API 与 Parallel Kernel API
现在我们来看看如何在 TornadoVM 中表示计算内核。TornadoVM 有两个 API:一个是我们在模糊滤镜示例中使用的 Parallel Loop API,另一个是 Parallel Kernel API。TornadoVM 的并行循环 API 是基于注解的。在使用这个 API 时,开发人员必须提供串行实现代码,然后考虑在哪里并行化循环。
一方面,开发速度加快了,因为开发人员只需要向现有的 Java 串行代码中添加注解就可以实现并行化。Parallel Loop API 适合非专业用户,他们不需要知道 GPU 的计算细节,也不需要知道应该使用哪种硬件。
另一方面,Parallel Loop API 可以使用的模式数量有限。在使用这个 API 时,开发人员可以使用典型的map/reduce模式运行应用程序。但其他的并行模式,如扫描或复杂模板,很难用这个 API 实现。此外,这个 API 不允许开发人员控制硬件,因为它是硬件无关的,但有时候开发人员确实需要控制硬件。此外,将现有的 OpenCL 和 CUDA 代码移植到 Java 可能会很困难。
为了应对这些限制,我们加入了 Parallel Kernel API。
用 Parallel Kernel API 实现模糊滤镜
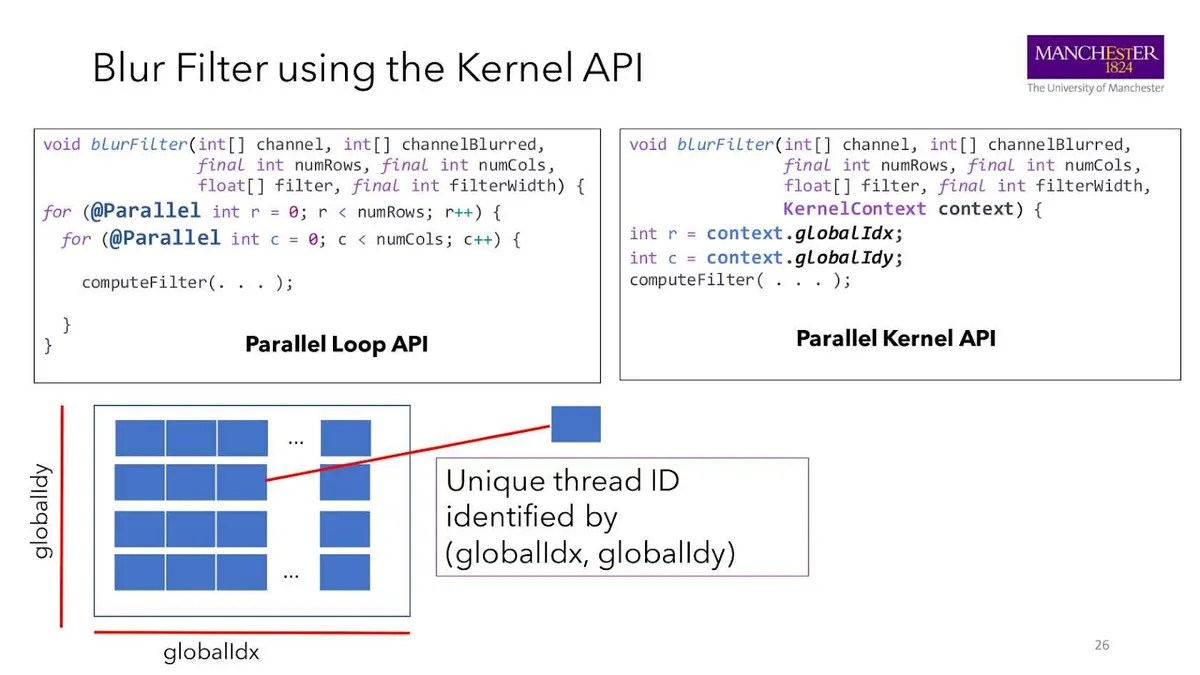
我们回到之前的例子:模糊滤镜。我们有两个并行循环,遍历图像的两个维度并应用滤镜。这可以转换成使用 Parallel Kernel API。
我们不使用两个循环,而是通过内核上下文引入隐式并行化。上下文是一个 TornadoVM 对象,用户可以通过它访问到每个维度的线程标识符、本地/共享内存、同步原语等。
在我们的示例中,滤镜的 X 轴和 y 轴坐标分别来自上下文的 globalIdx 和 globalIdy 属性,并像之前一样用于应用滤镜。这种编程风格更接近 CUDA 和 OpenCL 编程模型。

需要注意的是,TornadoVM 无法在运行时确定需要多少个线程。用户需要通过 worker 网格进行配置。
在这个例子中,我们用图像维度创建了一个 2D 的 worker 网格,并与函数名相关联。当用户的代码调用 execute()函数时,将网格作为参数传进去,进而应用相应的滤镜。
TornadoVM 的优势
但是,如果 Parallel Kernel API 更接近于底层的编程模型,为什么要使用 Java 而不是 OpenCL 和 PTX 或 CUDA 和 PTX,尤其是在有现有代码的情况下?
TornadoVM 还有其他的优势,比如实时任务迁移、自动内存管理和透明的代码优化,而且代码优化是根据不同的架构而进行的。
它还可以运行在 FPGA 上,具有完全透明和集成的编程工作流。你可以使用你最喜欢的 IDE,例如 IntelliJ 或 Eclipse,编写在 FPGA 上运行的代码。
它也可以部署在云端,如亚马逊云。你可以将代码移植到 Java 和 TornadoVM,以便免费获得所有这些功能。
性能
现在我们来谈谈性能。TornadoVM 可不仅仅被用于给图像应用滤镜,它也被用在金融科技或数学模拟(例如 Monte Carlo 或 Black-Scholes)领域。它还被用于计算机视觉应用、物理模拟、信号处理等其他领域。
上图对不同设备上的不同应用程序的执行情况进行了对比。同样,我们仍然将串行执行作为参考对象,条形表示加速因子,越高越好。
正如我们所看到的,我们有可能实现非常高的性能加速。例如,信号处理或物理模拟可以比Java的串行执行快4000倍。对这些结果的详细分析,可以参阅学术出版物。
TornadoVM 在行业的应用
业界的一些公司也在尝试使用 TornadoVM。上图是两个正在使用 TornadoVM 的应用场景。
其中一个应用场景来自卢森堡的 Neurocom 公司,用它运行一种自然语言处理算法。到目前为止,通过在 GPU 上运行分层聚类算法,已经实现了 30 倍的性能提升。
另一个应用场景来自 Spark Works 公司,这是一家位于爱尔兰的公司,用它处理来自物联网设备的信息。他们用强大的 GPU、GPU100 运行后处理工作负载。与 Java 相比,他们可以获得 460 倍的性能提升,已经相当好了。
你可以访问TornadoVM网站查看完整的应用场景列表。
总结
异构设备现在几乎出现在每一个计算系统中,这是不可避免的。它们就在这里,而且会一直这样下去。
因此,当前和未来软件系统的程序员需要面对广泛和多样化的设备,例如 GPU、FPGA 或任何其他即将出现的硬件。他们可以通过 TornadoVM 对这些设备进行编程。
TornadoVM 可以被看作是 Java 和 JVM 的高性能计算平台,可以与现有的 JDK(例如 OpenJDK)结合使用。
本文介绍了 TornadoVM,并简要解释了它的工作原理。此外,本文还通过一个用 Java 实现的图像处理示例演示了开发人员如何充分利用异构硬件。我们解释了 TornadoVM 中用于异构编程的两个 API:一个是 Parallel Loop API,适合普通开发人员使用;另一个是 Parallel Kernel API,适合已经了解 CUDA 和 OpenCL 并想要将现有代码移植到 TornadoVM 的专家使用。
作者简介:
Juan Fumero 是曼彻斯特大学的一名研究员。他的研究课题是异构高级编程语言虚拟机、GPGPU 和分布式计算。目前,他是 TornadoVM 项目的一员,为 Java 应用程序引入自动 GPU 和 FPGA JIT 编译和执行特性。他还与英特尔合作,将 oneAPI 引入 TornadoVM,用于对英特尔计算架构的代码进行优化。Juan 获得了爱丁堡大学的博士学位,主要研究在 GPU 上加速 Java、R 语言和 Ruby。此外,他曾在 Oracle 实验室和 CERN 实习,实现编译器,评估多核系统的并行技术。
了解更多软件开发与相关领域知识,点击访问 InfoQ 官网:,获取更多精彩内容!
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: wxii2p22




