


阅读本文大概需要5分钟
前面我写过一篇文章:这篇文章中我带大家回忆了一下冒泡排序、选择排序和插入排序三种经典的排序算法,他们的时间复杂度均为 O(N^2),效率不高。
这篇文章我们讨论一个高级一点排序算法:希尔排序。很多朋友看到一些算法的名字就望而却步,其实没有必要,我们每个人只要愿意迈出那一步,后面将会迎来更多更好的东西。这篇文章手把手带你学会希尔排序的原理,最后给出代码实现。

希尔排序是基于插入排序的,我们知道,插入排序有个弊端,假设一个很小的数据项在很靠近右端的位置上,那么所有的中间数据项都必须向右移动一位,这个步骤对每一个数据项都执行了将近N次的复制,这也是插入排序效率为 O(N^2) 的原因。
希尔排序的中心思想是将数据进行分组,然后对每一组数据进行插入排序,在每一组数据都有序后,再对所有的分组利用插入排序进行最后一次排序。这样可以显著减少数据交换的次数,以达到加快排序速度的目的。
这种思想需要依赖一个增量序列,我们称为 n-增量,n 表示进行排序时数据项之间的间隔,习惯上用 h 表示。为了很好的理解增量排序,我们看下面的示意图:
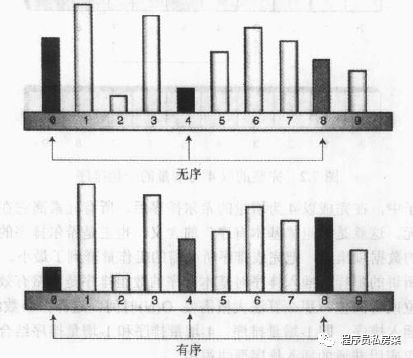
上图显示了增量为 4 时对 10 个数据项进行排序的示意图,一趟后 0、4、8 三个位置上的数据项已经排好序,接下来,算法向右移动一步,对 1、5、9 三个位置的数据项进行排序,这个过程一直持续进行,直到所有数据项都完成了一次 4-增量排序,然后缩小增量,再重复上面的过程,最后一次增量为 1,对所有的数据项进行一次插入排序,从而完成了希尔排序的全部步骤。因为最后一趟都已经基本有序了,所以复杂度没有向普通插入排序那么大了。
说到这里,大家应该可以明白,增量序列在希尔排序中是很重要的。一般好的增量序列都有 2 个共同的特征:
这篇文章中我们使用增量序列用 h = 3 * h + 1 来生成。h 初值被赋予 1,然后使用该公式生成序列 1、4、13、40、121、364 等等,当间隔大于数组大小的时候停止,使用序列的最大数组作为间隔开始希尔排序过程,然后没完成一次排序,用倒推公式 h = (h – 1) / 3 来减小间隔,保证最后一次 h=1,完成最后一次插入排序。
说完了原理,下面看看具体实现代码:
public void shellSort2() {
int h = 1;
while(h <= nElem / 3) {
h = h * 3 + 1; //增量间隔
}
while(h > 0) {
for(int i = h; i < nElem; i++) {
//每个增量间隔内,实现插入排序,两个for循环和插入排序一样,只不过第二个for循环里参数略有调整而已,和h有关
for(int j = i; j < nElem; j += h) {
for(int k = j; (k - h >= 0) && a[k] < a[k - h]; k -= h) {
swap(k, k-h);
}
}
}
h = (h-1) / 3;
}
}
算法分析:希尔排序时间复杂度平均为 O(NlogN),最好与最坏情况要根据具体的增量序列来判断,对于不同的增量序列有不同的复杂度。希尔排序的性能优于直接插入排序,因为在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来随着增量逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但是由于已经局部排过序了,所以已经接近有序状态,新的一趟排序过程也较快。因此,希尔排序在效率上较直接插入排序有较大的改进。
希尔排序是不稳定的,因为不同的间隔对应的数据是独自比较的,如果 a=b,但是不在同一个间隔上,显然会出现前后颠倒的情况,所以希尔排序是不稳定的。
空间复杂度为 O(1),不需要额外的存储空间。

END
人之所以能,是相信能!这世上没有天才,你若对得起时间,时间便对得起你。关注我们,每天进步一点点,利用碎片化时间学习。
我的世界不仅仅是coding
往期精彩:
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: wxii2p22




