


Java岗位面试,JVM是对程序员基本功考察,通常会问你对JVM了解吗?
可以分几部分回答这个问题,首先JVM内存划分 | JVM垃圾回收的含义 | 有哪些GC算法 以及年轻代和老年代各自特点等等。
1) JVM内存划分:
① 方法区 (线程共享) 常量 静态变量 JIT(即时编译器)编译后代码也在方法区存放
② 堆内存(线程共享) 垃圾回收的主要场地
③ 程序计数器 当前线程执行的字节码的位置指示器
④ Java虚拟机栈(栈内存) :保存局部变量,基本数据类型以及堆内存中对象的引用变量
⑤ 本地方法栈 (C栈):为JVM提供使用native方法的服务
通过这幅图了解一下
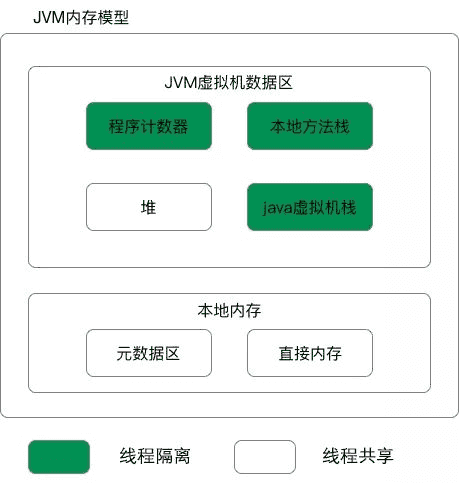
JDK 1.8同JDK 1.7 最大的区别是:元数据取代了永久代.元空间的本质和永久代类似,都是对JVM规范中的方法区的实现.其元空间和永久代之间的最大区别在于:元数据空间不在虚拟机中,而是在本地内存中
详细了解一下各个部分
01)程序计数器(PC寄存器)
程序计数器的定义:程序计数器是一块较小的内存空间,是当前线程正在执行的哪一条字节码指令的地址,若当前线程正在执行的是一个本地方法,那么此时程序计数器为Undefined
程序计数器的作用:
程序计数器的特点
02)Java虚拟机栈
定义:描述Java方法运行过程的内存模型
Java虚拟机栈会为每一个即将运行的Java方法创建一块叫做”栈帧”的区域,用于存放该方法运行过程中的一些信息,如 局部变量表 /操作数栈 /动态链接 /方法出口信息 ………….
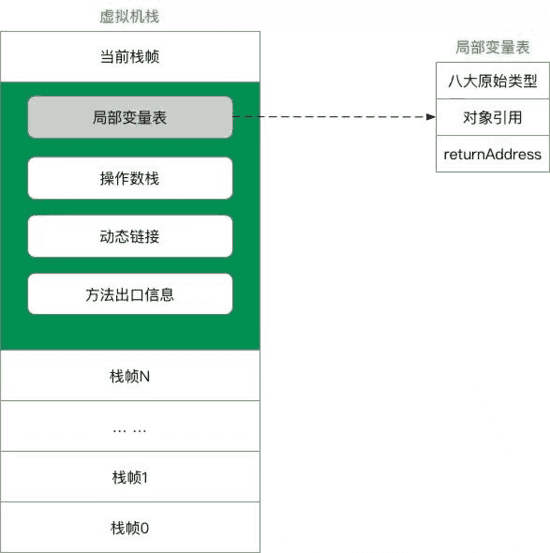
压栈出栈过程:
当方法运行过程中需要创建局部变量时,就将局部变量的值存入栈帧的局部变量表中
Java虚拟机栈的栈顶是当前正在执行的活动栈,也就是当前正在执行的方法,PC寄存器也会指向这个地址,只有这个活动的栈帧的本地变量可以被操作数栈操作,当前这个栈帧中调用另一个方法,与之对应的额栈帧又会被创建,新创建的栈帧压入栈顶,变成当前的活动栈帧,方法结束后,当前栈帧的返回值变成新的活动栈帧的中的操作数栈的一个操作数,如果没有返回值,那么新的活动栈帧中操作数栈的操作数没有变化
由于Java虚拟机栈是线程对应的,数据不是共享的,因此不用关心数据一致性问题,也不会存在同步锁的问题
特点
03)本地方法栈(C栈)
定义:是为了JVM运行native方法准备的空间,由于很多native方法都是用C语言实现的,所以通常又叫C栈,它与Java虚拟机栈实现的功能类似,只不过本地方法栈描述本地方法运行过程的内存模型
栈帧变化过程:
本地方法被执行时,在本地方法栈也会创建一块栈帧,用于存放该方法的局部变量表 /操作数栈 /动态链接 /方法出口等信息; 方法结束后,相应的栈帧也会出栈,并释放内存空间.也会抛出StackOverFlowError和OutOfMemoryError异常
04) 堆
定义:堆是用来对象的内存空间,几乎所有的对象都存储在堆中
特点:
05)方法区
定义:Java虚拟机规范中定义方法区是堆的一个逻辑部分,方法区存放以下信息 已被虚拟机加载的类信息 /常量 /静态变量 /即时编译后代码
特点:
运行时常量池:
方法区中存放:类信息 常量 静态变量 即时编译器变编译后代码.常量就存放在运行时常量池中.当类被Java虚拟机加载后,.class文件中的常量就存在方法区的运行常量池,而且在运行期间,可以向常量池中添加新的常量,如String类的intern()方法就能在运行期间向常量池中添加字符串常量
06) 直接内存(堆外内存)
直接内存是除Java虚拟机之外的内存,但有可能被Java使用
操作直接内存:
在NIO中引入了一种基于通道和缓存的IO方式,他可以调用本地方法的直接分配Java虚拟机之外的内存,然后通过一个存储在堆中的DirectByteBuffer对象直接操作该内存,而无需将外部内存中数据复制到堆中再进行操作,从而提高数据操作的效率,直接内存的大小不受Java虚拟机,也会抛出OutOfMemoryError异常
直接内存和堆内存比较:
2)类似 -Xms -Xmn这些参数的含义
堆内存分配
① : JVM初始分配的内存由-Xms指定,默认是物理内存的1/64
②: JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4
③: 默认空余堆内存小于40%时,JVM就会增加堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制
④: 因此服务器一般设置-Xms -Xmx相等以避免在每次GC后调整堆大小. 对象的堆内存由成为垃圾回收器的自动内存管理系统回收
非堆内存分配:
①:JVM使用-XX:PermSize 设置非堆内存的初始值,默认物理内存的1/64;
② :由XX:MaxPermSize设置设置最大非堆内存的大小
③: -Xmn2G :设置年轻代的大小为2G
④ :-XX:SurvivorRatio ,设置年轻代中Eden区与Survivor区的比值
3)垃圾回收的算法有哪些?
① 引用计数法:原理是在此对象有个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回收时,只收集计数为0的对象.此算法的最致命的无法处理循环引用的问题
②: 标记-清除 :此算法分两个阶段,第一阶段从引用的根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除,此算法需要暂停应用,同时产生内存碎片
③: 复制算法 此算法把内存划分为两个相等的区域,每次只使用一个区域,垃圾回收时,遍历当前使用的区域,把正在使用的对象复制到另一个区域中每次算法每次只处理正在使用的对象,因此复制的成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现”碎片问题”,此算法的缺点也很明显,需要两倍的内存空间
④: 标记-整理:此算法结合了”标记-清除”和:复制算法的两个的优点,也是分两个阶段,第一个阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,清除未标记的对象并且把存活的对象”压缩”到堆的其中一块,按顺序排放,,此算法避免”标记-清除”的碎片问题,同时也避免”复制”的空间问题
4)root搜索算法中,哪些可以作为root?
来源:cnblogs.com/developerxiaofeng/p/9214969.html
整编:Java技术栈(公众号id: javastack)
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: wxii2p22




