

要说排序算法里面比较简单的,我觉得直接插入排序算是一个。
直接插入排序的原理很简单,就是把一个数字插入到一个有序的数组中。
比如有这么一个数组:
1,3,5,7然后要把 4 插进去。
过程不难,4跟 7 比,7大,把 7 往后移动;
4跟 5 比,5大,把 5 往后移动;
4跟 3 比,3小,于是直接把4放到第三个位置上。
但是问题又来了,去哪找一个有序的数组,排序本来就是没有顺序的。
于是就有了一个理论,如果一个数组中只有一个元素,那么它一定是有序的。
比如有这么一个数组:
6 4 5 3 7
先把 6 当作一个单独的数组,那么它一定是有序的。
把 4 插入到这个有序的数组中,先把 4 记下来,4跟 6 比,6向后移动,然后把 4 放到第一个位置。
4 6 5 3 7接下来再把 5 插入到4 6这个有序的数组中,过程一样。
4 5 6 3 7循环下去,最终一定会得到一个有序的数组。
代码也不难。
void insert_sort(int *a, int size){int i, j, num;for (i = 1; i < size; i++){num = a[i];for (j = i - 1; j >= 0; j--){if (num < a[j]){a[j + 1] = a[j];}else{break;}}a[j + 1] = num;}}int main(){int num, arr[SIZE] = {0}, i;//随机产生数组srand(time(NULL));for (i = 0; i < SIZE; i++){arr[i] = rand() % 100;}insert_sort(arr, SIZE);for (i = 0; i < SIZE; i++){printf("%d ", arr[i]);}printf("n");return 0;}
直接插入排序的效率很低,基本上跟冒泡是一个级别。
问题就出在移动的次数太多。
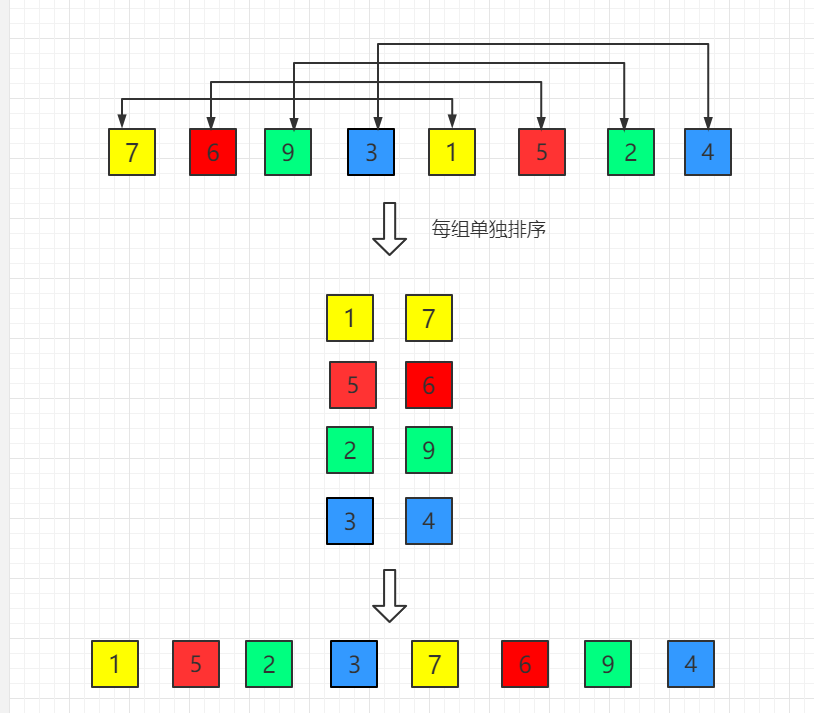
6 4 5 3 7比如 3 这个元素,最终应该放在 6 这个位置上,但是这个过程需要跟每个数字比较并且向后移动。
于是有个叫做希尔的人就提出了改进思路,如果能让 3 跳着来,速度就会提高很多。后来就有了希尔排序。
第一步,先选取 2 作为步长,就是长度的一半希尔排序,把原数组分成了两个数组,一个是6 5 7,一个是4 3,对这两个数组分别做直接插入排序。
6 5 74 3
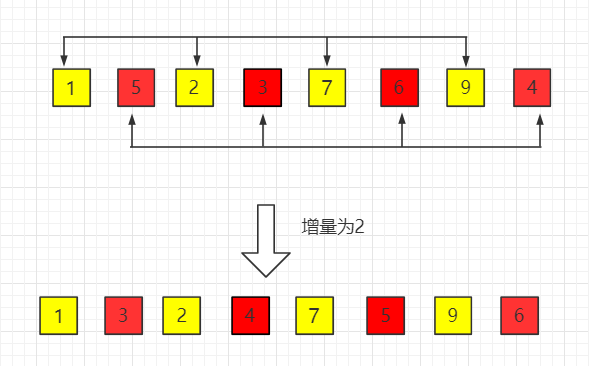
你会发现,这一次 3 直接和 4 交换了位置,一下子跳了两步。
第二步,步长再缩减一半,就是1。
其实就是对整个数组做直接插入排序。有些同学可能会有疑问,既然最终也是对整个数组做直接插入排序,为什么不一开始就这样?随着步长的逐渐的缩减希尔排序,数组会变得基本有序,虽然最后一步也是直接插入排序,但是移动的元素会很少。希尔排序的效率要比直接插入排序高很多。
代码也只需要做简单的修改。
void shell_sort(int *a, int size){int i, j, num, h;for (h = size / 2; h > 0; h /= 2){for (i = h; i < size; i++){num = a[i];for (j = i - h; j >= 0; j = j - h){if (num < a[j]){a[j + h] = a[j];}else{break;}}a[j + h] = num;}}}int main(){int num, arr[SIZE] = {0}, i;//随机产生数组srand(time(NULL));for (i = 0; i < SIZE; i++){arr[i] = rand() % 100;}shell_sort(arr, SIZE);for (i = 0; i < SIZE; i++){printf("%d ", arr[i]);}printf("n");return 0;}
最后来试下 5 万个数据排序,两者的差距肉眼可见。
root@Turbo:test# time ./insert_sortreal 0m1.740suser 0m1.724ssys 0m0.000sroot@Turbo:test# time ./shell_sortreal 0m0.008suser 0m0.004ssys 0m0.004sroot@Turbo:test#




