

前言
这两天在脉脉上有一个帖子很火,主题居然是讨论数据建模的,太令我诧异了!这个时候脉脉上不应该都是在炫耀年终奖和新Offer么?
这个帖子是一位百度的同学在吐槽,为啥阿里的《大数据之路》讲的好像很牛,但是为什么跟我们实际工作中的情况不一样啊?
“你们数据建模真的搞的那么牛*么?”
接需求、拉数据、做宽表、对数、跑批、找bug、重跑…
这就是大多数大数据工程师的工作日常,说好的建模呢?为什么我每天就是在建宽表?
书在说谎?
这个哥们的疑问,其实很有意思。脉脉上吵成一团,但都没说到真正的点上。
下面有个哥们说,写数据建模的内容,理论来源就是二位老爷子,避免不了要抄一些内容。说的好像有点道理。
但是你有没有想过这个问题,就是为什么这位同学会问这个问题?
因为他从书上看到的,跟他实际工作不一样。
那为什么书上和工作中不一样?是书上说谎了吗?
书上不是说要反规范化维度、缓慢变化维、快照维表么?为啥我工作上都没用到呢?
那些极限存储的拉链表呢?还有代理键呢?你们阿里就那么牛,建模都建出花儿了,就我在这里天天拉宽表?
唉,想知道这个问题的答案,咱还得翻翻旧账,说说数据仓库的超级痛点。
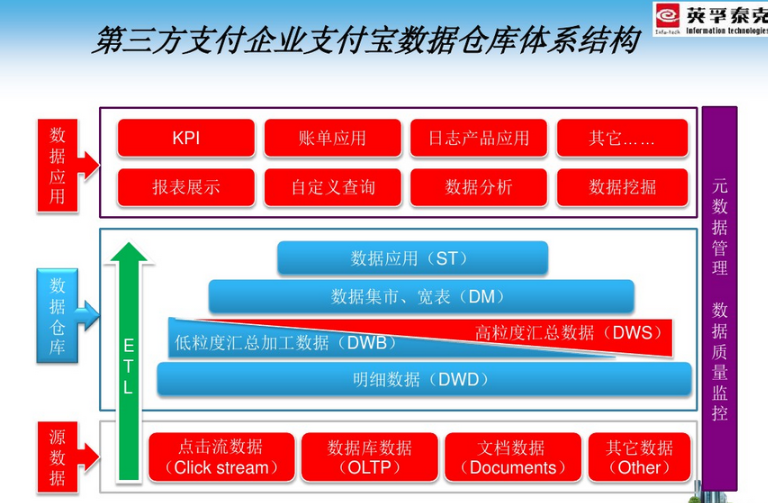
数仓的弱点
Inmon提出数据仓库构想的前几年,数仓项目建设成功概率有多少呢?80%以上,全部失败!
是不是有点像最近两年的“数据中台”?
为啥?当时数仓界的几位大佬也在研究。经过Inmon、Kimball一堆大佬的研究,以及对企业失败经验的总结,最后得出这么个结论:
就是如果按照Inmon老爷子的逻辑,从上到下去搞全面建设,实施周期往往非常长,往往要1-2年以上。
等实施完,很可能当时提需求的人都不知道当时自己想干啥了。
因此,Kimball老爷子基于多年咨询项目的经验,提出了缩小建设范围,提高成功率的方法。也就是现在常说的,自下而上的Kimball建设模式。
当然,全面建设的方法同样在发展,各大厂商针对不同的行业,输出了N个标准模型,比如Teradata的FSLDM、IBM的BDWM、IAA、IIW、Sybase的IWS等等。都是行业标杆,能直接推到逻辑建模的后半部分。
Inmon老爷子后来也跟Kimball一众大佬一起优化,并最终提出了CIF企业信息工厂的概念。
顺便八卦一句:Inmon和Kimball两位大佬并不是网上传闻完全割裂的,CIF里还致谢过Kimball,并且Kimball也否认有绝对的自上而下和自下而上的建设方法,都是结合着来的。
但即便是这样,数仓建设周期和业务需求即时性之间的GAP,仍然是一个弱点。
在以前,这个弱点还好,因为大家的业务变化的还是比较符合预期的,又有Kimball的缩小建设范围的法子,也有行业标准LDM,建设成功率就非常快了。
但是!现在!大清都亡了啊~~~!
你看看我们现在的市场环境,你用啥能满足那些不给数据就坐在你旁边的运营同学们!!!
你用啥办法能搞定一个月变一次的业务方向???请Inmon、Kimball大爷过来也做不到啊!
我分别为传统企业和互联网企业做过KPI考核体系。在传统企业,基本上是一次设计,然后基本上就不用管了,因为绩效考核政策基本上一年才会换一次。
但是在互联网公司,我就炸了!他们的绩效是一个月发布一次!!!
所以,数仓建设周期这个曾经让数仓项目大面积失败的弱点,在互联网时代,再次被无限放大,成为致命的弱点。
快速变化的业务,让我们根本没时间建模!
互联网数仓
当运营、产品同学坐在你旁边,看着你干活,你是啥感觉?我不知道你是什么感受。
反正有人在背后,我会立刻启动原始的危险生理报警。如果一直在旁,那感觉,如锋芒在背,如鲠在喉!恨不得立刻离开这个地方,还需要压制住一股揍扁他的冲动。
所以,为了送走这尊瘟神,我们只能是直接给他拖一张宽表啊!
我们再把场景放大一些,我们数仓组,对于数据分析师、运营、产品同学的迫切需求,我们会怎么对待?
这边业务推进会上,好一些的,会把数仓的同学叫过去。不好的,直接扔给你一个需求,项目下周上线,数据也要同步上线。
更恶劣的,项目都上线了,再过来跟你说需求。你就说怎么弄???
一方面,新业务根本没有通用的模型。另一方面,根本没足够的时间。你再牛,建模手段再牛,你总得先梳理业务流程吧?
但是新业务,业务流程可能都没人能给你说清楚。
好,你业务捋顺了,你是不是要看看数据?但是新业务,连数据都没有啊!而且,还有一堆的新功能在设计呢,表都没有,你咋建模?
纵使你有72般变化,千般手段,万般才能,也只能见招拆招,还是丢一个宽表给他,赶紧让他走吧!
所以导致现在互联网团队招人,比较少的找小半年没产出的数据建模师,而是去选择偏向能立刻出活儿,解决任务、调度、优化等问题的大数据工程师。
书到底有没有说谎?
是的,不可否认,拉宽表就是现如今数仓、大数据工程师的日常。
但是同学,你忘记了一个很重要的因素了。这就是历史。
可能有些新入行的人不知道,阿里巴巴当年把Teradata、Oracle、东南融通等国内外做数仓、数据治理的公司都挖了一个遍,组建了全国最牛的数据团队。
按照当时对数据的respect ,必须是一板一眼,规规矩矩的做。即便是后来去IOE,走了一批人,但数据至上的传统已然刻下来了。
现在还有人吐槽,说阿里的那些人,就是仗着自己有数据权限,到处瞎BB。
唉,哥们,你知道为什么我们做数据的这么苦B么?还不是因为没有话语权?业务什么都定好了,只让我们干活啊。
所以才会一点时间都不留给我们,导致我们天天拉宽表!
来,你说数仓项目成功最重要的因素是什么?
是规范!是彻底执行的规范!你没有话语权,谁搭理你?谁按你的规范行事?
你出台一堆的标准、规范,业务一句话就踩死你:今晚上线!你能怎么办?
所以,恰恰是阿里的数据部门有足够的权限(权力),设置了非常健全的游戏规则,这才有了阿里大数据的蓬勃发展。
所以我完全相信阿里《大数据之路》中写的那些内容,一来,当时的阿里,有高度统一的数据认知;二来,阿里有很好的数据团队基础;三来,数据团队有非常高的权限(权力)。
这三点,让阿里的数据团队至少不会因为业务部门无理的要求而节省建模的流程。
当然啊,现在很多互联网公司也开始重视数据仓库的建设,也都各自在数仓方向有非常多的布局。
我手上也有很多资料。感兴趣的同学可以翻到文末,下载来学习一下。
数仓新玩意
另外一方面,由于大数据技术的普及,以及各种对效率要求超高的场景的出现,大数据数仓领域也出现了一些新的小工具,比如宽表模型、BitMap、布隆过滤器等等。
在互联网以前,没人提宽表,都是业务库设计的逻辑,严格符合三范式,设计成窄表。
有些人以为窄表就是字段少,宽表就是字段多。其实不是哈。
宽窄的区分不是字段的多少,而是“是否冗余字段”。
如果一张表中,已经包括了所有你要取的字段,包括id、代码值、数值,不需要再关联其他表,那就是宽表。
BitMap则是一个高度压缩的信息,把每一个用户的某种信息离散为0、1。比如用户当天是否上线,然后横过来变成一个超长的“01010011101101”的字符串。
每天一长串,然后想要连续7天都上线的用户,只需要把这几个字符串做一个“and”操作,选出所有值为“1”的位,所对应的用户就是想要的结果了。
感兴趣的可以参考我之前写的一篇文章:【】
布隆过滤器也很有意思,原理是hash+位图的,典型应用是快速找库里是否有这个信息。把所有的信息hash散列成为一个数,然后映射到位图上。想要判断库里是否有这个信息,去这位图上看看就行了。因为是hash,所以任何信息都能放,比如图片、连接、文件都行。
感兴趣的可以参考我之前写的一篇文章:【】
消失的玩意
有新的玩法,就有消失的玩意。
比如说代理键,以前非常火,是用来解耦数仓代码体系和业务系统代码体系的。现在要么统一id,要么就用原来的id。
比如说拉链表,这可是很好用的方法啊,最新数据和历史数据都在一起,状态的变化可以随时拉出来。但是现在已经沦为极限存储的法子了。
还有什劳子缓慢变化维、快速维等等。
你还知道哪些消失的玩意?可以在群里一起唠一唠啊~
结语
感谢阅读,本次分享的内容就结束了。本公众号目前保持日更3000字,为你提供优秀的数据领域的分享。
原创
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: wxii2p22




